Statistical sample. Interval estimation of the general share
Sample
Sample or sampling frame- a set of cases (subjects, objects, events, samples), using a certain procedure, selected from the general population for participation in the study.
Sample characteristics:
- Qualitative characteristics of the sample - who exactly we choose and what methods of sample construction we use for this.
- The quantitative characteristic of the sample is how many cases we select, in other words, the sample size.
Need for sampling
- The object of study is very broad. For example, consumers of the products of a global company are a huge number of geographically dispersed markets.
- There is a need to collect primary information.
Sample size
Sample size- the number of cases included in the sample. For statistical reasons, it is recommended that the number of cases be at least 30-35.
Dependent and independent samples
When comparing two (or more) samples important parameter is their dependence. If it is possible to establish a homomorphic pair (that is, when one case from sample X corresponds to one and only one case from sample Y and vice versa) for each case in two samples (and this basis of relationship is important for the trait measured in the samples), such samples are called dependent. Examples of dependent selections:
- pair of twins
- two measurements of any feature before and after experimental exposure,
- husbands and wives
- etc.
If there is no such relationship between the samples, then these samples are considered independent, for example:
Accordingly, dependent samples always have the same size, while the size of independent samples may differ.
Samples are compared using various statistical criteria:
- and etc.
Representativeness
The sample may be considered representative or non-representative.
An example of a non-representative sample
- Study with experimental and control groups, which are placed in different conditions.
- Study with experimental and control groups using a paired selection strategy
- Study using only one group - experimental.
- A study using a mixed (factorial) plan - all groups are placed in different conditions.
Sample types
Samples are divided into two types:
- probabilistic
- improbability
Probability samples
- Simple probability sampling:
- Simple resampling. The use of such a sample is based on the assumption that each respondent is equally likely to be included in the sample. Based on the list of the general population, cards with the numbers of respondents are compiled. They are placed in a deck, shuffled, and a card is taken out of them at random, a number is written down, then returned back. Further, the procedure is repeated as many times as the sample size we need. Minus: repetition of selection units.
The procedure for constructing a simple random sample includes the following steps:
1. you need to get a complete list of members of the general population and number this list. Such a list, recall, is called the sampling frame;
2. determine the expected sample size, that is, the expected number of respondents;
3. retrieve from table random numbers as many numbers as we need sample units. If the sample should include 100 people, 100 random numbers are taken from the table. These random numbers can be generated by a computer program.
4. select from the base list those observations whose numbers correspond to the written random numbers
- A simple random sample has obvious benefits. This method is extremely easy to understand. The results of the study can be extended to the study population. Most approaches to statistical inference involve collecting information using a simple random sample. However, the simple random sampling method has at least four significant limitations:
1. It is often difficult to create a sampling frame that would allow for a simple random sample.
2. A simple random sample can result in a large population, or a population distributed over a large geographic area, which significantly increases the time and cost of data collection.
3. the results of applying a simple random sample are often characterized by low accuracy and greater standard error than the results of applying other probabilistic methods.
4. As a result of the application of the SRS, an unrepresentative sample may be formed. Although the samples obtained by simple random selection, on average, adequately represent the general population, some of them extremely incorrectly represent the population under study. The probability of this is especially high with a small sample size.
- Simple non-repetitive sampling. The procedure for constructing the sample is the same, only the cards with the numbers of the respondents are not returned back to the deck.
- Systematic probability sampling. It is a simplified version of a simple probability sample. Based on the list of the general population, respondents are selected at a certain interval (K). The value of K is determined randomly. The most reliable result is achieved with a homogeneous general population, otherwise the step size and some internal cyclic patterns of the sample may coincide (sample mixing). Cons: the same as in a simple probability sample.
- Serial (nested) sampling. The sampling units are statistical series (family, school, team, etc.). The selected elements are subjected to continuous examination. The selection of statistical units can be organized according to the type of random or systematic sampling. Cons: Possibility of greater homogeneity than in the general population.
- Zoned sample. In the case of a heterogeneous population, before using probability sampling with any selection technique, it is recommended to divide the population into homogeneous parts, such a sample is called a zoned sample. The zoning groups can be both natural formations (for example, city districts) and any feature underlying the study. The sign on the basis of which the division is carried out is called the sign of stratification and zoning.
- "Convenient" selection. The "convenience" sampling procedure consists in establishing contacts with "convenient" sampling units - with a group of students, a sports team, with friends and neighbors. If it is necessary to obtain information about people's reactions to a new concept, such a sample is quite reasonable. "Convenience" sampling is often used for preliminary testing of questionnaires.
Incredible Samples
The selection in such a sample is carried out not according to the principles of chance, but according to subjective criteria - accessibility, typicality, equal representation, etc.
- Quota sampling - the sampling is built as a model that reproduces the structure of the general population in the form of quotas (proportions) of the studied characteristics. Number of sample items with different combination of the studied characteristics is determined in such a way that it corresponds to their share (proportion) in the general population. So, for example, if we have a general population of 5,000 people, of which 2,000 women and 3,000 men, then in the quota sample we will have 20 women and 30 men, or 200 women and 300 men. Quota samples are most often based on demographic criteria: gender, age, region, income, education, and others. Cons: usually such samples are not representative, because it is impossible to take into account several social parameters at once. Pros: easily accessible material.
- Snowball method. The sample is constructed as follows. Each respondent, starting with the first, is asked to contact his friends, colleagues, acquaintances who would fit the selection conditions and could take part in the study. Thus, with the exception of the first step, the sample is formed with the participation of the objects of study themselves. The method is often used when it is necessary to find and interview hard-to-reach groups of respondents (for example, respondents with high incomes, respondents belonging to one professional group, respondents who have any similar hobbies / passions, etc.)
- Spontaneous sampling - sampling of the so-called "first comer". Often used in television and radio polls. The size and composition of spontaneous samples is not known in advance, and is determined by only one parameter - the activity of the respondents. Disadvantages: it is impossible to establish what kind of general population the respondents represent, and as a result, it is impossible to determine representativeness.
- Route survey - often used if the unit of study is the family. On the map locality where the survey will be performed, all streets are numbered. With the help of a table (generator) of random numbers are selected big numbers. Each large number is considered as consisting of 3 components: street number (2-3 first numbers), house number, apartment number. For example, the number 14832: 14 is the street number on the map, 8 is the house number, 32 is the apartment number.
- Zoned sampling with selection of typical objects. If, after zoning, a typical object is selected from each group, i.e. an object that approaches the average in terms of most of the characteristics studied in the study, such a sample is called zoned with the selection of typical objects.
6.Modal selection. 7. expert sample. 8. Heterogeneous sample.
Group Building Strategies
The selection of groups for their participation in a psychological experiment is carried out using various strategies, which are necessary in order to ensure the greatest possible compliance with internal and external validity.
Randomization
Randomization, or random selection, is used to create simple random samples. The use of such a sample is based on the assumption that each member of the population is equally likely to be included in the sample. For example, to make a random sample of 100 university students, you can put papers with the names of all university students in a hat, and then get 100 pieces of paper out of it - this will be random selection (Goodwin J., p. 147).
Pairwise selection
Pairwise selection- a strategy for constructing sample groups, in which groups of subjects are made up of subjects that are equivalent in terms of side parameters that are significant for the experiment. This strategy is effective for experiments using experimental and control groups with the best option- attracting twin pairs (mono- and dizygotic), as it allows you to create ...
Stratometric selection
Stratometric selection- randomization with the allocation of strata (or clusters). At this method sampling, the general population is divided into groups (strata) with certain characteristics (gender, age, political preferences, education, income level, etc.), and subjects with the corresponding characteristics are selected.
Approximate modeling
Approximate modeling- drawing up limited samples and generalizing the conclusions about this sample to a wider population. For example, when participating in a study of students in the 2nd year of university, the data of this study are extended to "people aged 17 to 21 years." The admissibility of such generalizations is extremely limited.
Approximate modeling is the formation of a model that, for a clearly defined class of systems (processes), describes its behavior (or desired phenomena) with acceptable accuracy.
Notes
Literature
Nasledov A. D. Mathematical Methods psychological research. - St. Petersburg: Speech, 2004.
- Ilyasov F. N. Representativeness of survey results in marketing research. Sotsiologicheskie issledovaniya. 2011. No. 3. P. 112-116.
see also
- In some types of studies, the sample is divided into groups:
- experimental
- control
- Cohort
Links
- The concept of sampling. The main characteristics of the sample. Sample types
Wikimedia Foundation. 2010 .
Synonyms:See what "Selection" is in other dictionaries:
sample- a group of subjects representing a certain population and selected for an experiment or study. The opposite concept is the totality of the general. The sample is part of the general population. Dictionary practical psychologist. M .: AST, ... ... Great Psychological Encyclopedia
sample- sampling The part of the general population of elements that is covered by the observation (often called the sampling population, and the sample is the method of sampling observation itself). In mathematical statistics, it is accepted ... ... Technical Translator's Handbook
- (sample) 1. A small quantity of a commodity selected to represent its entire quantity. See: sale by sample. 2. A small amount of product given to potential buyers to give them the opportunity to spend it ... ... Glossary of business terms
Sample- part of the general population of elements that is covered by the observation (it is often called the sampling population, and the sampling is the method of sampling observation itself). In mathematical statistics, the principle of random selection is adopted; this is… … Economic and Mathematical Dictionary
- (sample) Random selection of a subgroup of elements from the main population, the characteristics of which are used to evaluate the entire population as a whole. Sampling is used when it is too long or too expensive to survey the entire population... Economic dictionary
Cm … Synonym dictionary
Part of the objects from the population selected for study in order to draw a conclusion about the entire population. In order for the conclusion obtained by studying the sample to be extended to the entire population, the sample must have the property of being representative.
Sample representativeness
The property of the sample to correctly reflect the general population. The same sample may or may not be representative of different populations.
Example:
A sample consisting entirely of Muscovites who own a car does not represent the entire population of Moscow.
The sample of Russian enterprises with up to 100 employees does not represent all enterprises in Russia.
The sample of Muscovites making purchases in the market does not represent the purchasing behavior of all Muscovites.
At the same time, these samples (subject to other conditions) can perfectly represent Muscovite car owners, small and medium Russian enterprises and buyers shopping in the markets, respectively.
It is important to understand that sample representativeness and sampling error are different phenomena. Representativeness, unlike error, does not depend on sample size.
No matter how much we increase the number of surveyed Muscovites-car owners, we will not be able to represent all Muscovites with this sample.
Sampling error (confidence interval)
The deviation of the results obtained with the help of sample observation from the true data of the general population.
There are two types of sampling error: statistical and systematic. The statistical error depends on the sample size. How larger size sample, the lower it is.
Example:
For a simple random sample of 400 units, the maximum statistical error (with 95% confidence) is 5%, for a sample of 600 units - 4%, for a sample of 1100 units - 3% .
The systematic error depends on various factors that have a constant impact on the study and bias the results of the study in a certain direction.
Example:
- The use of any probability sample underestimates the proportion of high-income people who lead an active lifestyle. This happens due to the fact that such people are much more difficult to find in any particular place (for example, at home).
The problem of respondents who refuse to answer the questions of the questionnaire (the share of "refuseniks" in Moscow, for different surveys, ranges from 50% to 80%)
In some cases, when true distributions are known, bias can be leveled out by introducing quotas or reweighting the data, but in most real studies, even estimating it can be quite problematic.
Sample types
Samples are divided into two types:
probabilistic
improbability
Probability samples
1.1 Random sampling (simple random selection)
Such a sample assumes the homogeneity of the general population, the same probability of the availability of all elements, the presence complete list all elements. When selecting elements, as a rule, a table of random numbers is used.
1.2 Mechanical (systematic) sampling
A kind of random sample, sorted by some attribute (alphabetical order, phone number, date of birth, etc.). The first element is selected randomly, then every 'k'th element is selected in increments of 'n'. The size of the general population, while - N=n*k
1.3 Stratified (zoned)
It is used in case of heterogeneity of the general population. The general population is divided into groups (strata). In each stratum, selection is carried out randomly or mechanically.
1.4 Serial (nested or clustered) sampling
With serial sampling, the units of selection are not the objects themselves, but groups (clusters or nests). Groups are selected randomly. Objects within groups are surveyed all over.
Incredible Samples
The selection in such a sample is carried out not according to the principles of chance, but according to subjective criteria - accessibility, typicality, equal representation, etc.
Quota sampling
Initially, a certain number of groups of objects are allocated (for example, men aged 20-30 years, 31-45 years and 46-60 years; persons with an income of up to 30 thousand rubles, with an income of 30 to 60 thousand rubles and with an income of more than 60 thousand rubles ) For each group, the number of objects to be surveyed is specified. The number of objects that should fall into each of the groups is set, most often, either in proportion to the previously known share of the group in the general population, or the same for each group. Within the groups, objects are selected randomly. Quota samples are used quite often in marketing research.
Snowball Method
The sample is constructed as follows. Each respondent, starting with the first, is asked to contact his friends, colleagues, acquaintances who would fit the selection conditions and could take part in the study. Thus, with the exception of the first step, the sample is formed with the participation of the objects of study themselves. The method is often used when it is necessary to find and interview hard-to-reach groups of respondents (for example, respondents with a high income, respondents belonging to the same professional group, respondents who have some similar hobbies / passions, etc.)
2.3 Spontaneous sampling
The most accessible respondents are polled. Typical examples of spontaneous sampling are surveys in newspapers/magazines, questionnaires given to respondents for self-completion, most Internet surveys. The size and composition of spontaneous samples is not known in advance, and is determined by only one parameter - the activity of the respondents.
2.4 Sample of typical cases
Units of the general population are selected that have an average (typical) value of the attribute. This raises the problem of choosing a feature and determining its typical value.
Implementation of the research plan
This stage, we recall, includes the collection of information and its analysis. The process of implementing a marketing research plan typically requires the most research and is the source of the greatest error.
When collecting statistical data, a number of shortcomings and problems arise:
firstly, some respondents may not be in the agreed place and they have to be contacted again or replaced;
secondly, some respondents may be uncooperative or give biased, knowingly false answers.
Thanks to modern computing and telecommunication technologies, data collection methods are developing and improving.
Some firms conduct surveys from a single center. In this case, professional interviewers sit in offices and dial random phone numbers. If they hear the response of callers, the interviewer asks the person who answered the phone to answer a few questions. The latter are read from the computer monitor screen and the respondents' answers are typed on the keyboard. This method eliminates the need for formatting and encoding data, reduces the number of errors.
Selective research.
The concept of the sampling method.
Selective observation- this is such a non-continuous observation, in which the selection of units of the population to be studied is carried out randomly, the selected part is subjected to research, after which the results are distributed to the entire population.
The sampling method is used when
1 when the observation itself is associated with damage or destruction of the observed units (yarn for spice, electric light bulb for combustion product)
2 large aggregate volume
3 high costs (financial and labor).
Usually, 5-10% of the total population is subjected to a sample survey, less often 15-25%.
The purpose of sample observation is to determine the characteristics of the general average and general share(P). Characteristics of the sample population - sample mean  and the sample fraction (w) differ from the general characteristics by the amount of sampling error (
and the sample fraction (w) differ from the general characteristics by the amount of sampling error (  ). Therefore, it is necessary to calculate the sampling error or the representativeness error, which is determined by formulas developed in probability theory for each type of sample and selection method.
). Therefore, it is necessary to calculate the sampling error or the representativeness error, which is determined by formulas developed in probability theory for each type of sample and selection method.
There are the following ways to select units:
1 return ball selection, commonly referred to as resampling.
With repeated selection, the probability of getting each individual unit into the sample remains constant, because after selecting a unit, it is returned to the population again and can be selected again.
2 selection according to the unreturned ball scheme, called random sampling. In this case, each selected unit is not returned back, and the probability of getting individual units into the sample changes all the time (for the remaining units it will increase) (lot), tables of random numbers, for example, 75 out of 780.
Sample types.
1 Actually - random.
This is one in which the selection of units in the sample is made directly from the entire mass of units in the general population.
In this case, the number of selected units is usually determined based on the accepted proportion of the sample.
For a sample, there is the ratio of the number of units in the sample population and the number of units in the general population N.

So, with a 5% sample from a batch of goods of 2000 units, the sample size n is 100 units. (  ), and with a 20% sample it will be 400 units.
), and with a 20% sample it will be 400 units.
( )
)
An important condition for a proper random sample that each unit of the population is given an equal opportunity to be included in the sample.
With random selection, the marginal sampling error for the mean  is equal to
is equal to


 - sampling variance
- sampling variance
n - sample size
t is the confidence factor, which is determined from the table of values of the Laplace integral function for a given probability P.
With non-repetitive sampling, the marginal sampling error is determined by the formula for the average

where N is the size of the general population of the share

To determine the ash content of coal, 100 samples of coal were examined randomly. As a result of the survey, it was found that the average ash content of coal in the sample is 16%,  = 5%. In 10 samples, the ash content of coal was > 20% with a probability of 0.954 to determine the limits in which the average ash content of coal in the deposit and the proportion of coal with an ash content > 20% will be
= 5%. In 10 samples, the ash content of coal was > 20% with a probability of 0.954 to determine the limits in which the average ash content of coal in the deposit and the proportion of coal with an ash content > 20% will be
Average ash content

determine the marginal sampling error

 2*0.5=1%
2*0.5=1%
at p=0.954 t=2

share of coal with ash content >20%

the sample share is determined

where m is the proportion of units that have a feature

sampling error for share

With a probability of 0.954, it can be argued that the proportion of coal with an ash content of more than 20% in the deposit will be within
P= 10%+(-)6% or 
mechanical sampling.
This is a kind of actually - random. In this case, the entire population is divided into n equal parts, and then one unit is selected from each part.
All units of the population must be arranged in a certain order. At the same time, in relation to the indicator under study, the units of the general population can be ordered according to a significant, secondary or neutral feature. In this case, the unit that is in the middle of each group should be selected from each group. This avoids sampling bias.
Apply: when examining buyers in stores, visitors in clinics, every 5,4,3, etc.
Example mechanical sampling
To determine the average term of using a short-term loan in a bank, a 5% mechanical sample will be made, which includes 100 accounts. As a result of the survey, it was found that average term using a short-term loan 30 days with  9 days in 5 accounts Loan term > 60 days.
9 days in 5 accounts Loan term > 60 days.
Sampling error


those. with a probability of 0.954 it can be argued that the term of using the loan fluctuates
1 within 30days+(-)2days, i.e. 
2 shares of loans with a term > 60 days.

the sample share will be

determine the share error

with a probability of 0.954, it can be argued that the share of bank loans with a maturity of >60 days will be within
Typical sample.
The general population is divided into homogeneous typical groups. Then, from each typical group, an individual selection of units into the sample is made by a random or mechanical sample.
For example: pr. tr. workers, consisting of separate groups by qualification.
Important feature- gives more accurate results compared to others, tk. the sample includes a typological unit.
The selection of units of observation in the sample set is carried out by various methods. Consider a typical sample with proportional selection within typical groups.
The sample size from a typical group in the selection proportional to the number of typical groups is determined by the formula

where  =V samples from typical group
=V samples from typical group
 = V of the typical group.
= V of the typical group.
The marginal error of the sample mean and proportion for a non-repetitive random and mechanical selection method within typical groups is calculated by the formulas



where  = sample variance
= sample variance
Example: typical sample
To determine the average age of men entering marriage, a 5% sample was made in the district with the selection of units in proportion to the number of typical groups
Mechanical selection was used within the groups
With a probability of 0.954 determine the limits in which they will be average age men who remarry and the proportion of men who remarry.

average age of marriage for men in the sample

marginal sampling error

with a probability of 0.954 it can be argued that the average age of men entering into marriage will be within

for men entering into a second marriage be within

the sample share is determined

the sample variance of the alternative feature is
with a probability of 0.954 it can be argued that the proportion of those who marry a second time is within

serial sampling.
With serial sampling, the population is divided into groups of the same size - series. The sample population is selected series. Within the series, a continuous observation of the units that fell into the series is carried out.
With repetitive selection  and
and  determined by the formula
determined by the formula

where  - interseries variance
- interseries variance

where  sample mean of the series
sample mean of the series
 sample mean of serial sample
sample mean of serial sample
R- number of series of the general population
r - number of selected series
Example: in the workshop of 10 brigades, in order to study their labor productivity, a 20% serial sample will be carried out, which included 2 brigades. As a result of the survey, it was found that 
 with a probability of 0.997 to determine the limits within which the average output of the shop workers will be.
with a probability of 0.997 to determine the limits within which the average output of the shop workers will be.

the sample mean of a serial sample is determined by the formula

with a probability of 0.997 it can be argued that the average output of the shop workers is within 

There are 200 boxes of parts, 40 pieces in each box, in the finished product warehouse of the workshop. For quality check finished products 10% serial sampling will be made. As a result of the sampling, it was found that for defective parts is 15%. The serial sample variance is 0.0049.
With a probability of 0.997, determine the limits in which the proportion of defective products in a batch of boxes is
The proportion of defective parts will be within

determine the marginal sampling error for the share by the formula

with a probability of 0.997 it can be argued that the proportion of defective parts
in the party is within 

In the practice of designing sample observation, there is a need to find the size of the sample, which is necessary to ensure a certain accuracy in the calculation of general characteristics - the average and the proportion.
The marginal sampling error, the probability of its occurrence, and the variation of the feature are known in advance.
With random re-selection the sample size is determined by the formula

with random non-repetitive and mechanical selection, the sample size

for a typical sample

for serial sampling

For example, 2000 families live in the district.
It is planned to conduct a sample survey of them by the method of random non-repetitive selection to find the average family size.
Determine the required sample size, provided that with a probability of 0.954 the sampling error does not exceed 1 person with a standard deviation of 3 people.

10 thousand people live in the city. families. Using mechanical sampling, it is proposed to determine the proportion of families with three or more children. What should be the sample size for the sampling error to be less than 0.02 with a probability P=0.954 if the variance is known to be 0.02 from previous surveys?
sample types:
Actually-random;
Mechanical;
typical;
Serial;
Combined.
Self-random sampling consists in the selection of units from the general population at random or at random without any elements of consistency. However, before making proper random selection, it is necessary to make sure that all units of the general population without exception have absolutely equal chances of getting into the sample, there are no gaps in the lists or list, ignoring individual units, etc. Clear boundaries should also be established for the population so that the inclusion or exclusion of individual units is not in doubt. So, for example, when examining students, it is necessary to indicate whether persons on academic leave, students of non-state universities, military schools, etc. will be taken into account; when surveying commercial establishments, it is important to determine whether the general population will include trade pavilions, commercial tents and other similar objects. Self-random selection can be both repeated and non-repeated. For non-repetitive selection during the drawing of lots, the drawn lots are not returned to the original set and do not participate in the further selection. When using tables of random numbers, non-repeating selection is achieved by skipping numbers if they are repeated in the selected column or columns.
Mechanical sampling is used in cases where the general population is somehow ordered, i.e. there is a certain sequence in the arrangement of units (employee numbers of employees, voter lists, telephone numbers of respondents, numbers of houses and apartments, etc.).
The general population during mechanical selection can be ranked or ordered according to the value of the trait being studied or correlated with it, which will increase the representativeness of the sample. However, in this case, the risk of a systematic error increases, associated with an underestimation of the values of the studied trait (if the first value is recorded from each interval) or with its overestimation (if the last value is recorded from each interval). Therefore, it is advisable to start the selection from the middle of the first interval
typical selection. This method of selection is used in cases where all units of the general population can be divided into several typical groups. When surveying the population, such groups can be, for example, districts, social, age or educational groups, when surveying enterprises - an industry or sub-sector, form of ownership, etc. Typical selection involves the selection of units from each typical group by actual random or mechanically. Since representatives of all groups necessarily fall into the sample population in one or another proportion, the typification of the general population makes it possible to exclude the influence of intergroup dispersion on the average sampling error, which in this case is determined only by intragroup variation.
The selection of units in a typical sample can be organized either in proportion to the volume of typical groups, or in proportion to the intragroup differentiation of a trait.
serial selection. This method of selection is convenient in cases where the population units are grouped into small groups or series. Packages with a certain amount of finished products, batches of goods, student groups, brigades and other associations can be considered as such series. The essence of serial sampling lies in the actual random or mechanical selection of series, within which a complete survey of units is carried out.
 What should be the diet during pregnancy?
What should be the diet during pregnancy? Medical Robotics
Medical Robotics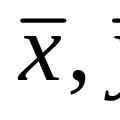 Analysis and interpretation of the results of the study Checking the significance of the correlation
Analysis and interpretation of the results of the study Checking the significance of the correlation