Ingen biologisk slumptalssensorlåda. Sensorer för slumpmässiga och pseudo-slumpmässiga tal. Gpsc i kryptografi
Det finns tre fundamentalt olika sätt att erhålla tal som används som slumpmässiga: fysiska, tabellformade och algoritmiska.
Man tror att det första försöket att skapa en fysisk generator av slumptal går tillbaka till 3500 f.Kr. och förknippas med brädspelet senet, en forntida egyptisk sekulär underhållning. Enligt moderna rekonstruktioner av spelets regler användes fyra platta pinnar för att bestämma antalet poäng som varje spelare fick och sekvensen av drag i detta spel, vars ena sida var vit, den andra - svart. Pinnarna kastades samtidigt och, beroende på kombinationen av färger som föll, bestämde de ytterligare möjligheter för spelarna. I början av XX-talet. sekvenser av slumpmässiga nummer simulerades manuellt - genom att kasta ett mynt eller en tärning, lägga ut spelkort, använda ett roulettehjul, ta bort kulor från en urna, etc. Moderna fysiska (hårdvaru)sensorer är speciella enheter som genererar slumpmässiga tal baserat på omvandlingen av slumpmässiga ljud av naturligt eller artificiellt ursprung (termiskt brus, skotteffekt i vakuumrör, radioaktivt sönderfall, etc.). Till exempel en bil ERNIE 4 (elektronisk slumptalsindikatorutrustning),
- 1 Ibland, men sällan, hänvisas till fördelningen i tabellen som standard 0 1 ... 8 9
- 0,1 0,1 ... 0,1 0,1 / med hjälp av vilken de vinnande numren i det månatliga British Lottery bestäms, använder det termiska bruset från transistorer som en källa till slumpmässiga variabler. Den fysiska metoden för att erhålla en sekvens av slumptal har egenskaper som är nackdelar för en simuleringsmodell. Dessa inkluderar först och främst behovet av speciella åtgärder för att säkerställa stabiliteten hos signalkällan, omvandlad till slumptal, och omöjligheten att reproducera den resulterande sekvensen av slumptal.
Tabeller med slumptal är fria från dessa nackdelar. Låt oss förklara vad som menas med en tabell med slumptal. Antag att vi har implementerat N oberoende experiment, som resulterade i slumptal a, a 2, osdr. Att skriva ner dessa siffror (i ordning efter utseende och i form av en rektangulär tabell) kommer att ge vad som kallas en slumptalstabell. Den används enligt följande. Under beräkningarna kan vi behöva antingen ett slumptal eller ett slumptal. Om ett slumptal krävs kan vi ta vilket nummer som helst från den här tabellen. Detsamma gäller fallet med ett slumpmässigt heltal - vilken siffra som helst kan väljas för varje siffra. Om vi behöver ett slumptal 0 k av på varandra följande siffror cc, a 2, ao /, och antar att 8 = (Hoco ^ .- kan vara i en rad, kan du använda valfri urvalsalgoritm som inte beror på värdena av tabellens siffror, börja från var som helst i tabellen, läs i valfri riktning.
De första tabellerna med slumptal erhölls med hjälp av rouletter. Sådana tabeller har publicerats flera gånger i form av böcker. En av de mest kända tabellerna, som publicerades 1927, innehöll över 40 000 slumptal "slumpmässigt hämtade från folkräkningsrapporter."
Historisk referens
Leonard Tippett (Leonard Henry Caleb Tippett, 1902-1985) - Engelsk statistiker, elev till K. Pearson och R. Fisher. Åren 1965-1966. - Ordförande för Royal Statistical Society. Några viktiga resultat i teorin om extrema värden är förknippade med hans namn, till exempel Fisher - Tippett-fördelningen och Fisher - Tippett - Gnedenko-satsen.
Senare konstruerades speciella enheter (maskiner) som mekaniskt genererar slumptal. Den första sådana maskinen användes 1939 av M.J. Kendall och B. Babington-Smith för att skapa tabeller med 100 000 slumpmässiga siffror. År 1955 företaget RAND Corporation publicerade välkända tabeller med en miljon slumpmässiga siffror som erhållits av en annan maskin av denna typ. Den praktiska tillämpningen av tabeller med slumptal är för närvarande begränsad till problem som använder slumpmässiga urvalsmetoder.
prover, till exempel i sociologisk forskning eller vid statistisk acceptanskontroll av kvaliteten på styckeprodukter för olika ändamål.
Det är intressant
I Ryssland är GOST 18321-73 (ST SEV 1934-79) i kraft, som fastställer reglerna för att välja enheter av produkter i ett prov under statistisk godkännande kvalitetskontroll, statistiska metoder för analys och reglering av tekniska processer för alla typer av bitar produkter för industriella ändamål och konsumentvaror. I det anges särskilt att vid val av produktionsenheter i urvalet "används tabeller med slumpmässiga nummer enligt ST SEV 546-77".
återansöka; alla siffror är lätta att reproducera; och utbudet av nummer i en sådan sekvens är begränsat. En sekvens av pseudoslumptal har dock en uppenbar fördel jämfört med en tabell: det finns enkla formler för att beräkna ett pseudoslumptal, medan att få varje nummer endast tar 3-5 kommandon, och beräkningsprogrammet tar bara upp ett fåtal celler i drevet.
Det finns många algoritmer för att erhålla sekvenser av pseudoslumptal, implementeringar av sådana algoritmer, kallade sensorer (generatorer) av pseudoslumptal, beskrivs i detalj i speciallitteratur. Här är några av de mest välkända algoritmerna.
- Tippett L. Slumpmässiga urvalsnummer. London: Cambridge University Press, 1927.
- Se: D.E. Knut, Konsten att programmera. 3:e uppl. M.: Williams, 2000. T. 2. Ch. 3. Slumptal.
Deterministisk PRNG
Ingen deterministisk algoritm kan generera helt slumpmässiga tal, den kan bara approximera vissa egenskaper hos slumptal. Som John von Neumann sa, " alla som har en svaghet för aritmetiska metoder för att erhålla slumptal är utan tvekan synd».
Alla PRNG med begränsade resurser fastnar förr eller senare i en loop - den börjar upprepa samma nummersekvens. Längden på PRNG-cyklerna beror på själva generatorn och är i genomsnitt cirka 2 n/2, där n är storleken på det interna tillståndet i bitar, även om linjära kongruenta och LFSR-generatorer har maximala cykler i storleksordningen 2 n. Om en PRNG kan konvergera till för korta cykler blir PRNG förutsägbar och oanvändbar.
De flesta enkla aritmetiska generatorer, även om de är snabba, lider av många allvarliga nackdelar:
- Period/perioder för korta.
- Konsekutiva värden är inte oberoende.
- Vissa bitar är "mindre slumpmässiga" än andra.
- Ojämn endimensionell fördelning.
- Reversibilitet.
Särskilt stordatoralgoritmen visade sig vara mycket dålig, vilket väckte tvivel om tillförlitligheten av resultaten från många studier som använder denna algoritm.
PRNG med entropikälla eller RNG
Tillsammans med det befintliga behovet av att generera lätt reproducerbara sekvenser av slumptal, finns det också ett behov av att generera helt oförutsägbara eller helt enkelt helt slumpmässiga tal. Sådana generatorer kallas slumptalsgeneratorer(RNG - eng. slumptalsgenerator, RNG). Eftersom sådana generatorer oftast används för att generera unika symmetriska och asymmetriska nycklar för kryptering, är de oftast byggda av en kombination av en stark PRNG och en extern entropikälla (och det är denna kombination som numera vanligtvis förstås som en RNG) .
Nästan alla stora mikrochipstillverkare levererar hårdvaru-RNG:er med olika entropikällor och använder olika metoder för att rensa dem från den oundvikliga förutsägbarheten. Men för tillfället matchar inte hastigheten för att samla in slumptal av alla befintliga mikrochips (flera tusen bitar per sekund) hastigheten hos moderna processorer.
I persondatorer använder RNG-programförfattare mycket snabbare källor till entropi, som ljudkortsbrus eller processorklockräkning. Innan det blev möjligt att läsa värdena på klockräknaren var samlingen av entropi den mest sårbara punkten i RNG. Detta problem är fortfarande inte helt löst i många enheter (t.ex. smarta kort) som förblir sårbara på detta sätt. Många RNG:er använder fortfarande traditionella (föråldrade) metoder för att samla in entropi, som att mäta användarens respons (musrörelser, etc.), som till exempel i, eller interaktioner mellan trådar, som till exempel i Java säker slumpmässig.
Exempel på RNG- och entropikällor
Några exempel på RNG:er med deras entropikällor och generatorer:
| Entropikälla | PRNG | Värdighet | nackdelar | |
|---|---|---|---|---|
| / dev / random på Linux | Processorcykelräknare, men samlas bara in under hårdvaruavbrott | LFSR, med utdata hashing | Det "värms upp" under mycket lång tid, det kan "fastna" under lång tid, eller det fungerar som en PRNG ( / dev / urandom) | |
| Rölleka av Bruce Schneier | Traditionella (föråldrade) metoder | AES -256 och | Flexibel kryptografisk design | "Värmar upp" under lång tid, mycket litet internt tillstånd, beror för mycket på den kryptografiska styrkan hos de valda algoritmerna, långsam, tillämplig uteslutande för nyckelgenerering |
| Generator Leonid Yuriev | Ljudkort brus | ? | Mest troligt en bra och snabb källa till entropi | Ingen oberoende, känd för att vara kryptografiskt stark PRNG, tillgänglig exklusivt som Windows |
| Microsoft | Inbyggd i Windows, "fastnar inte" | Litet inre tillstånd, lätt förutsägbart | ||
| Interaktion mellan trådar | Java har inget annat val än, stort internt tillstånd | Långsam entropisamling | ||
| Kaos av Ruptor | Processorcykelräknare, samlas in kontinuerligt | Hashing ett 4096-bitars internt tillstånd baserat på en icke-linjär variant av Marsaglia-generatorn | Tills det snabbaste av allt, stora inre tillstånd, inte "fastnar" | |
| RRAND av Ruptor | Processorcykelräknare | Krypterar internt tillstånd med strömchiffer | Mycket snabbt, internt tillstånd av godtycklig storlek efter val, "fastnar inte" |
PRNG i kryptografi
Ett slags PRNG är PRBG - generatorer av pseudo-slumpmässiga bitar, såväl som olika strömchiffer. PRNG, som strömchiffer, består av ett internt tillstånd (vanligtvis från 16 bitar till flera megabyte i storlek), en funktion för att initiera det interna tillståndet med en nyckel, eller utsäde(eng. utsäde), interna tillståndsuppdateringsfunktioner och utgångsfunktioner. PRNG:er är uppdelade i enkla aritmetiska, brutna kryptografiska och kryptografiska. Deras gemensamma syfte är att generera sekvenser av tal som inte kan särskiljas från slumpmässiga med beräkningsmetoder.
Även om många starka PRNGs eller strömchiffer erbjuder mycket mer "slumpmässiga" tal, är sådana generatorer mycket långsammare än konventionella aritmetiska generatorer och kanske inte lämpar sig för någon form av forskning som kräver att processorn är fri för mer användbara beräkningar.
För militära ändamål och i fält används endast klassificerade synkrona kryptografiskt starka PRNG (strömchiffer), blockchiffer används inte. Exempel på välkända kryptografiskt starka PRNG:er är ISAAC, SEAL, Snow, den mycket långsamma teoretiska algoritmen Blum, Blum och Shub, samt räknare med kryptografiska hashfunktioner eller kryptografiskt starka blockchiffer istället för en utdatafunktion.
Hårdvara PRNG
Bortsett från de föråldrade, välkända LFSR-generatorerna som användes i stor utsträckning som hårdvaru-PRNG:er på 1900-talet, är tyvärr väldigt lite känt om moderna hårdvaru-PRNG:er (strömchiffer), eftersom de flesta av dem är designade för militära ändamål och hålls hemliga . Nästan all befintlig kommersiell hårdvaru-PRNG är patenterad och hålls också hemlig. Hårdvaru-PRNG:er begränsas av strikta krav på det förbrukade minnet (oftast är användning av minne förbjuden), hastighet (1-2 klockcykler) och area (flera hundra FPGAs - eller
På grund av bristen på bra hårdvaru-PRNG:er tvingas tillverkare använda de mycket långsammare men allmänt kända blockchiffrorna som finns tillgängliga (Computer Review # 29 (2003)
Den första algoritmen för att erhålla pseudoslumptal föreslogs av J. Neumann. Det kallas mid-squas-metoden.
Låt ett fyrsiffrigt tal R 0 = 0,9876. Låt oss kvadrera det. Vi får ett 8-siffrigt nummer R 0 2 = 0,97535376. Låt oss välja 4 mellersta siffror från detta nummer och sätta R 1 = 0,5353. Sedan kvadrerar vi det igen och extraherar de 4 mittentalen från det. Vi får R 2 etc. Denna algoritm har inte bevisat sig själv. Det visade sig mer än nödvändigt små värden av R i .
Det är dock av intresse att undersöka kvaliteten på denna generator med en högerförskjuten siffervalsgrupp för R i 2 :
där a är maxvärdet för bråkdelen för en given dator (till exempel a = 8).
b är antalet decimaler i talet R i(till exempel 5).
INT (A) - heltalsdel av ett tal.
För a = 8, b = 5, R 0 = 0,51111111 på PKZX-Spectrum, cirka 1200 icke-repeterande nummer erhålls.
Träning: Studien bör utföras med varierande a, b, R 0 ... Hitta till vilka värden a, b, R 0 den största längden L av en sekvens av icke-repeterande tal erhålls med "bra" stokastiska parametrar. Fastställ om värdet på R påverkar 0 på sensorns kvalitet. Om det gör det, bestäm sedan området för "acceptabla" värden för parametern R 0 ... Presentera resultaten av att testa den optimala varianten av värdena a, b, R 0 .
Multiplikativa algoritmer. Sensor # 2: Lehmer Linear Congruential Generator 1951.
var u i, M, C och p är heltal.
AmodB- resten av divisionen helt AnaB,
A mod B = A-B * INT (A/B)
Den genererade sekvensen har en upprepad cykel som inte överstiger p-tal.
Den maximala perioden erhålls för C0, men en sådan generator ger dåliga stokastiska resultat.
När C = 0 kallas generatorer för multiplikativ. De har de bästa stokastiska parametrarna. Formlerna för deras användning kallas också för avdragsmetoden.
Den mest populära metoden för att få pseudoslumptal är avdragsmetoden enligt följande formel:
var u i, M, p-heltal, 0
Om du väljer U 0 och M så att för R 0 = U 0 / p fick en irreducerbar fraktion och ta p och M ömsesidigt prime, sedan alla R i kommer att vara irreducerbara bråkdelar av formen: R i= U i/ sid.
Vi får den största (men inte mer än p) längden av en icke-repeterande talföljd. Värdena för U 0 , p och M kan bekvämt väljas från primtal.
Träning: Undersök för vad U 0 , p och M kommer längden av en sekvens av icke-repeterande tal att vara minst 10 000 för "bra" stokastiska parametrar. Bestäm om värdet på R påverkar 0 för Mip = konst på sensorns statistiska egenskaper. Om det gör det, bestäm sedan intervallet för tillåtna värden U 0 ... Presentera generatortestresultat för optimala värden på p, M och U 0 .
Sensor # 3: Modifiering av Korobov.

där p är ett stort primtal, till exempel 2027, 5087, ...
M är ett heltal som uppfyller villkoren:

n är ett heltal. De där. välj M nära p / 2 från uppsättningen av siffror M = p– 3 n.
Till exempel, för p = 5087 tar vi n = 7. Eftersom 3 7 = 2187 och 3 8 = 6561 kommer att vara större än p. Så: M = 5087-2187 = 2900.
Vi får nummer U i i intervallet = och talet R i i intervallet (0,1).
Träning: Välj den värld där de bästa statistiska parametrarna för sensorn och den största längden L. erhålls. Ta reda på om värdet på R påverkar 0 på sensorns stokastiska egenskaper och, om den gör det, bestäm sedan intervallet för tillåtna värden R 0 ... Presentera sensortestresultaten för optimala värden för M, pi och R 0 .
Observera att densitetskurvan för fördelningen av slumptal helst skulle se ut som den som visas i fig. 22.3. Det vill säga, i det ideala fallet innehåller varje intervall samma antal punkter: N i = N/k , var N- det totala antalet poäng, k- antalet intervaller, i= 1,…, k .
genereras av en idealgenerator teoretiskt
Man bör komma ihåg att generering av ett godtyckligt slumptal består av två steg:
- generering av ett normaliserat slumptal (det vill säga jämnt fördelat från 0 till 1);
- konvertera normaliserade slumptal r i till slumpmässiga siffror x i, som distribueras enligt den erforderliga användarlagen (godtycklig) distribution eller i det erforderliga intervallet.
Slumptalsgeneratorer är indelade i:
- fysisk;
- tabellform;
- algoritmisk.
Fysisk RNG
Ett exempel på en fysisk RNG är: ett mynt (huvuden - 1, svansar - 0); tärningar; en trumma med en pil uppdelad i sektorer med siffror; hårdvarubrusgenerator (HS), som används som en bullrig termisk enhet, till exempel en transistor (Fig. 22.4-22.5).
| Uppgiften "Generera slumptal med hjälp av ett mynt" | |
|
Använd ett mynt för att generera ett slumpmässigt 3-siffrigt nummer jämnt fördelat från 0 till 1. Precisionen är tre decimaler. |
|
Det första sättet att lösa problemet
Rita ett intervall från 0 till 1. Läs siffrorna i följd från vänster till höger, dela intervallet på mitten och välj varje gång en av delarna av nästa intervall (om det tappade 0, sedan det vänstra, om det tappade 1, sedan den högra). Således kan du komma till vilken punkt som helst i intervallet, så exakt du vill. Så, 1 : intervallet halveras - och, - höger halva väljs, intervallet minskas:. Nästa nummer, 0 : intervallet halveras - och, - vänster halva är vald, intervallet minskas:. Nästa nummer, 0 : intervallet halveras - och, - vänster halva är vald, intervallet minskas:. Nästa nummer, 1 : intervallet halveras - och, - höger halva väljs, intervallet minskas:. Genom villkoret för problemets noggrannhet har lösningen hittats: det är vilket tal som helst från intervallet, till exempel 0,625. I princip, om du närmar dig strikt, måste uppdelningen av intervallen fortsätta tills de vänstra och högra gränserna för det hittade intervallet SAMMANstämmer varandra med en noggrannhet på den tredje decimalen. Det vill säga, ur noggrannhetssynpunkt kommer det genererade numret inte längre att kunna särskiljas från vilket nummer som helst från det intervall i vilket det är beläget.
Det andra sättet att lösa problemet
|
RNG i tabellform
Tabellformade RNG:er använder speciellt sammanställda tabeller som innehåller verifierade okorrelerade, det vill säga oberoende av varandra, tal som en källa till slumpmässiga tal. Tabell 22.1 visar ett litet fragment av en sådan tabell. Genom att gå igenom tabellen från vänster till höger uppifrån och ned kan du få slumptal jämnt fördelade från 0 till 1 med det antal decimaler som krävs (i vårt exempel använder vi tre decimaler för varje nummer). Eftersom siffrorna i tabellen inte är beroende av varandra kan tabellen passeras på olika sätt, till exempel uppifrån och ned, eller från höger till vänster, eller säg att du kan välja nummer som är i jämna positioner.
| Tabell 22.1. Slumpmässiga siffror. Jämnt fördelade från 0 till 1 slumptal |
||||||||||||||||||||||||||||||||||||||||||||
| Slumpmässiga siffror | Jämnt fördelat från 0 till 1 slumptal |
|||||||
| 9 | 2 | 9 | 2 | 0 | 4 | 2 | 6 | 0.929 |
| 9 | 5 | 7 | 3 | 4 | 9 | 0 | 3 | 0.204 |
| 5 | 9 | 1 | 6 | 6 | 5 | 7 | 6 | 0.269 |
Fördelen med denna metod är att den ger verkligt slumpmässiga tal, eftersom tabellen innehåller verifierade okorrelerade tal. Nackdelar med metoden: det krävs mycket minne för att lagra ett stort antal siffror; stora svårigheter med att generera och kontrollera sådana tabeller, upprepningar när du använder en tabell garanterar inte längre slumpmässigheten i den numeriska sekvensen och därför tillförlitligheten av resultatet.
Det finns en tabell som innehåller 500 absolut slumpmässiga verifierade siffror (hämtad från boken av I. G. Venetsky, V. I. Venetskaya "Grundläggande matematiska och statistiska begrepp och formler i ekonomisk analys").
Algoritmisk RNG
Siffrorna som genereras med dessa RNG:er är alltid pseudoslumpmässiga (eller kvasi-slumpmässiga), det vill säga varje efterföljande genererat nummer beror på det föregående:
r i + 1 = f(r i) .
Sekvenser som består av sådana siffror bildar loopar, det vill säga det finns nödvändigtvis en cykel som upprepas ett oändligt antal gånger. De upprepade cyklerna kallas perioder.
Fördelen med RNG-data är hastighet; generatorer kräver praktiskt taget inga minnesresurser, de är kompakta. Nackdelar: talen kan inte helt kallas slumpmässiga, eftersom det finns ett beroende mellan dem, liksom närvaron av perioder i sekvensen av kvasi-slumpmässiga tal.
Överväg flera algoritmiska metoder för att erhålla en RNG:
- mellersta kvadratmetoden;
- metod för mellanprodukter;
- blandningsmetod;
- linjär kongruent metod.
Mean square metod
Det finns ett fyrsiffrigt nummer R 0. Denna siffra kvadreras och skrivs in R 1 . Längre ifrån R 1 tas den mellersta (fyra mittersta siffror) - ett nytt slumptal - och skrivs in R 0. Därefter upprepas proceduren (se fig. 22.6). Observera att det faktiskt inte är nödvändigt att ta som ett slumptal ghij, a 0.ghij- med en nolla och en decimalkomma tilldelad till vänster. Detta faktum återspeglas som i fig. 22.6 och i efterföljande liknande figurer.
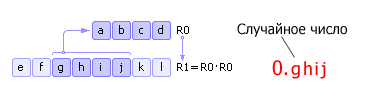 |
Nackdelar med metoden: 1) om vid någon iteration numret R 0 blir lika med noll, sedan urartar generatorn, så det är viktigt med rätt val av initialvärde R 0; 2) generatorn kommer att upprepa sekvensen igenom M n steg (i bästa fall), var n- sifferkapacitet R 0 , M- talsystemets bas.
Till exempel, i fig. 22,6: om nummer R 0 kommer att representeras i binär notation, sekvensen av pseudoslumptal kommer att upprepas i 2 4 = 16 steg. Observera att upprepning av sekvensen kan ske tidigare om det initiala numret inte är väl valt.
Metoden som beskrivs ovan föreslogs av John von Neumann och går tillbaka till 1946. Eftersom denna metod visade sig vara opålitlig, övergavs den snabbt.
Metod för mellanprodukter
siffra R 0 multipliceras med R 1, från det erhållna resultatet R 2 extrahera mitten R 2 * (detta är ett annat slumptal) och multiplicerat med R 1 . Alla efterföljande slumptal beräknas med detta schema (se fig. 22.7).
 |
Omrörningsmetod
Blandningsmetoden använder operationer för att cykliskt flytta innehållet i en cell till vänster och höger. Tanken med metoden är följande. Låt cellen lagra fröet R 0. Om vi cykliskt förskjuter cellens innehåll åt vänster med 1/4 av cellens längd får vi ett nytt nummer R 0 *. Likaså cykliskt skifta innehållet i en cell R 0 till höger med 1/4 av celllängden får vi det andra talet R 0 **. Summan av siffror R 0 * och R 0 ** ger ett nytt slumptal R 1 . Ytterligare R 1 är inskrivet R 0, och hela operationssekvensen upprepas (se figur 22.8).
 |
Observera att antalet som härrör från summeringen R 0 * och R 0 **, kanske inte passar helt i cellen R 1 . I detta fall ska extra siffror kasseras från det mottagna numret. Låt oss förklara detta för fig. 22.8, där alla celler representeras av åtta binära siffror. Låt vara R 0 * = 10010001 2 = 145 10 , R 0 ** = 10100001 2 = 161 10 , då R 0 * + R 0 ** = 100110010 2 = 306 10 ... Som du kan se upptar talet 306 9 siffror (i det binära talsystemet), och cellen R 1 (gilla R 0) kan innehålla maximalt 8 bitar. Därför innan du anger värdet i R 1 är det nödvändigt att ta bort en "extra", biten längst till vänster från talet 306, som ett resultat av vilket i R 1 blir inte 306, utan 00110010 2 = 50 10. Observera också att i språk som Pascal, "trunkering" av extra bitar när en cell svämmar över sker automatiskt i enlighet med den specificerade typen av variabel.
Linjär kongruent metod
Den linjära kongruenta metoden är en av de enklaste och mest använda procedurerna för att simulera slumptal. Denna metod använder moden ( x, y), som returnerar resten av det första argumentet dividerat med det andra. Varje efterföljande slumptal beräknas baserat på föregående slumptal med hjälp av följande formel:
r i+ 1 = mod ( k · r i + b, M) .
En sekvens av slumptal som erhålls med denna formel kallas linjär kongruent sekvens... Många författare kallar en linjär kongruent sekvens för b = 0 multiplikativ kongruent metod, och kl b ≠ 0 blandad kongruent metod.
För en högkvalitativ generator måste du välja lämpliga koefficienter. Det är nödvändigt att antalet M var ganska stor, eftersom perioden inte kan ha fler M element. Å andra sidan är uppdelningen som används i denna metod en ganska långsam operation, så det skulle vara logiskt för en binär dator att välja M = 2 N, eftersom i detta fall att hitta resten av divisionen reduceras inuti datorn till en binär logisk operation "AND". Det är också vanligt att välja det största primtalet M mindre än 2 N: i speciallitteraturen är det bevisat att i detta fall de minst signifikanta bitarna av det resulterande slumptalet r i+ 1 beter sig lika slumpmässigt som de äldre, vilket har en positiv effekt på hela sekvensen av slumptal som helhet. Ett exempel är ett av Mersenne-nummer lika med 2 31 - 1, och därmed M= 2 31 - 1.
Ett av kraven för linjära kongruenta sekvenser är största möjliga periodlängd. Periodens längd beror på värdena M , k och b... Teoremet som vi presenterar nedan låter oss avgöra om det är möjligt att uppnå en period med maximal längd för specifika värden M , k och b .
Sats... Linjär kongruent sekvens definierad av siffror M , k , b och r 0, har en längdperiod M om och endast om:
- siffrorna b och Mömsesidigt enkelt;
- k- 1 multipel sid för varje enkelt sid som är en divisor M ;
- k- 1 multipel av 4 om M multipel av 4.
Låt oss slutligen avsluta med ett par exempel på hur man använder den linjära kongruentialmetoden för att generera slumptal.
Det visade sig att en serie pseudoslumptal genererade från data från exempel 1 kommer att upprepas varje M/ 4 nummer. siffra q ställs in godtyckligt innan beräkningarna påbörjas, men man bör komma ihåg att serien ger intryck av att vara slumpmässig för stora k(vilket innebär att q). Resultatet kan förbättras något om b udda och k= 1 + 4 q - i det här fallet kommer raden att upprepas varje M tal. Efter ett långt letande k forskarna bestämde sig för värdena 69069 och 71365.
En slumptalsgenerator som använder data från exempel 2 kommer att producera slumpmässiga icke-repeterande tal med en period på 7 miljoner.
Den multiplikativa metoden för att generera pseudo-slumpmässiga tal föreslogs av D. H. Lehmer 1949.
Kontrollera kvaliteten på generatorn
Kvaliteten på hela systemet och noggrannheten i resultaten beror på kvaliteten på RNG. Därför måste den slumpmässiga sekvensen som genereras av RNG:n uppfylla ett antal kriterier.
De kontroller som utförs är av två typer:
- kontroller för enhetlig distribution;
- kontrollerar statistiskt oberoende.
Kontroller av enhetlighet i distributionen
1) RNG bör producera nära följande värden av statistiska parametrar som är karakteristiska för en enhetlig slumpmässig lag:
2) Frekvenstest
Frekvenstestet låter dig ta reda på hur många nummer som faller in i intervallet (m r σ r ; m r + σ r) det vill säga (0,5 - 0,2887; 0,5 + 0,2887) eller slutligen (0,2113; 0,7887). Eftersom 0,7887 - 0,2113 = 0,5774 drar vi slutsatsen att i en bra RNG bör cirka 57,7% av alla tappade slumptal falla in i detta intervall (se fig. 22.9).
vid kontroll av det för ett frekvenstest
Det är också nödvändigt att ta hänsyn till att antalet siffror som faller in i intervallet (0; 0,5) bör vara ungefär lika med antalet siffror som faller in i intervallet (0,5; 1).
3) Chi-kvadrattest
Chi-kvadrattest (χ 2 test) är ett av de mest kända statistiska testerna; det är den huvudsakliga metoden som används i kombination med andra kriterier. Chi-kvadrattestet föreslogs 1900 av Karl Pearson. Hans anmärkningsvärda arbete anses vara grunden för modern matematisk statistik.
För vårt fall kommer chi-kvadrattestet att tillåta oss att ta reda på hur mycket verklig RNG:n ligger nära RNG-standarden, det vill säga om den uppfyller kravet på enhetlig distribution eller inte.
Frekvensdiagram referens RNG visas i fig. 22.10. Eftersom distributionslagen för referens-RNG är enhetlig, är den (teoretiska) sannolikheten sid i slå in siffror i intervallet (alla dessa intervaller k) är lika med sid i = 1/k ... Och därmed i var och en av k intervaller kommer att falla slät på sid i · N tal ( NÄr det totala antalet genererade nummer).
En riktig RNG kommer att producera siffror fördelade (och inte nödvändigtvis jämnt!) k intervaller och varje intervall kommer att innehålla n i siffror (i summan n 1 + n 2 + ... + n k = N ). Hur kan vi avgöra hur bra den testade RNG är och hur nära referensen? Det är ganska logiskt att överväga kvadraterna av skillnaderna mellan det mottagna antalet siffror. n i och "referens" sid i · N ... Låt oss lägga till dem, och som ett resultat får vi:
χ 2 exp. = ( n 1 - sid 1 · N) 2 + (n 2 - sid 2 N) 2 + ... + ( n k sid k · N) 2 .
Det följer av denna formel att ju mindre skillnaden är i var och en av termerna (och därmed ju mindre värdet på χ 2 exp.), desto starkare fördelningen av slumptal som genereras av den verkliga RNG tenderar att vara enhetlig.
I det föregående uttrycket tilldelas var och en av termerna samma vikt (lika med 1), vilket i själva verket kanske inte motsvarar verkligheten; därför, för chi-kvadratstatistiken, är det nödvändigt att normalisera var och en i-th term genom att dividera den med sid i · N :
Slutligen skriver vi det resulterande uttrycket mer kompakt och förenklar det:
Vi har fått fram värdet av chi-kvadrattestet för experimentell data.
Tabell 22.2 ges teoretisk chi-kvadratvärden (χ 2 teori), där ν = N- 1 är antalet frihetsgrader, sidÄr den användardefinierade konfidensnivån som anger hur mycket RNG ska uppfylla kraven för enhetlig distribution, eller sid detta är sannolikheten att experimentvärdet för χ 2 exp. kommer att vara mindre än den tabellerade (teoretiska) χ 2-teorin. eller lika med honom.
| Tabell 22.2. Några procentenheter av χ 2-fördelningen |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| p = 1 % | p = 5 % | p = 25 % | p = 50 % | p = 75 % | p = 95 % | p = 99 % | |
| ν = 1 | 0.00016 | 0.00393 | 0.1015 | 0.4549 | 1.323 | 3.841 | 6.635 |
| ν = 2 | 0.02010 | 0.1026 | 0.5754 | 1.386 | 2.773 | 5.991 | 9.210 |
| ν = 3 | 0.1148 | 0.3518 | 1.213 | 2.366 | 4.108 | 7.815 | 11.34 |
| ν = 4 | 0.2971 | 0.7107 | 1.923 | 3.357 | 5.385 | 9.488 | 13.28 |
| ν = 5 | 0.5543 | 1.1455 | 2.675 | 4.351 | 6.626 | 11.07 | 15.09 |
| ν = 6 | 0.8721 | 1.635 | 3.455 | 5.348 | 7.841 | 12.59 | 16.81 |
| ν = 7 | 1.239 | 2.167 | 4.255 | 6.346 | 9.037 | 14.07 | 18.48 |
| ν = 8 | 1.646 | 2.733 | 5.071 | 7.344 | 10.22 | 15.51 | 20.09 |
| ν = 9 | 2.088 | 3.325 | 5.899 | 8.343 | 11.39 | 16.92 | 21.67 |
| ν = 10 | 2.558 | 3.940 | 6.737 | 9.342 | 12.55 | 18.31 | 23.21 |
| ν = 11 | 3.053 | 4.575 | 7.584 | 10.34 | 13.70 | 19.68 | 24.72 |
| ν = 12 | 3.571 | 5.226 | 8.438 | 11.34 | 14.85 | 21.03 | 26.22 |
| ν = 15 | 5.229 | 7.261 | 11.04 | 14.34 | 18.25 | 25.00 | 30.58 |
| ν = 20 | 8.260 | 10.85 | 15.45 | 19.34 | 23.83 | 31.41 | 37.57 |
| ν = 30 | 14.95 | 18.49 | 24.48 | 29.34 | 34.80 | 43.77 | 50.89 |
| ν = 50 | 29.71 | 34.76 | 42.94 | 49.33 | 56.33 | 67.50 | 76.15 |
| ν > 30 | ν + sqrt (2 ν ) · x sid+ 2/3 x 2 sid- 2/3 + O(1 / sqrt ( ν )) | ||||||
| x sid = | –2.33 | –1,64 | –0,674 | 0.00 | 0.674 | 1.64 | 2.33 |
Anses acceptabelt sid från 10 % till 90 %.
Om χ 2 exp. mycket mer än χ 2 teorin. (det är sid- bra), sedan generatorn inte tillfredsställer enhetlig fördelningskrav, eftersom de observerade värdena n i gå för långt ifrån teoretiska sid i · N och kan inte betraktas som slumpmässigt. Med andra ord är konfidensintervallet så stort att begränsningarna på siffrorna blir mycket lösa, kraven på siffrorna är svaga. I detta fall kommer ett mycket stort absolut fel att observeras.
Även D. Knut noterade i sin bok "Konsten att programmera" att ha χ 2 exp. liten är också i allmänhet inte bra, även om det vid första anblicken verkar underbart ur enhetlighetssynpunkt. Ta faktiskt en serie siffror 0,1, 0,2, 0,3, 0,4, 0,5, 0,6, 0,7, 0,8, 0,9, 0,1, 0,2, 0,3, 0,4, 0,5, 0,6, ... - de är idealiska ur synvinkel enhetlighet och χ 2 exp. kommer att vara praktiskt taget noll, men det är osannolikt att du känner igen dem som slumpmässiga.
Om χ 2 exp. mycket mindre än χ 2 teorin. (det är sid- lite), sedan generatorn inte tillfredsställer kravet på en slumpmässig enhetlig fördelning, eftersom de observerade värdena n i för nära teoretiskt sid i · N och kan inte betraktas som slumpmässigt.
Men om χ 2 exp. ligger i ett visst intervall, mellan två värden på χ 2 teor. som motsvarar t.ex. sid= 25 % och sid= 50%, då kan vi anta att värdena för slumptal som genereras av sensorn är helt slumpmässiga.
Dessutom bör man komma ihåg att alla värderingar sid i · N måste vara tillräckligt stor, till exempel fler än 5 (får ut empiriskt). Först då (med ett tillräckligt stort statistiskt urval) kan de experimentella förhållandena anses vara tillfredsställande.
Så verifieringsproceduren är som följer.
Statistiska oberoende tester
1) Kontrollera frekvensen av förekomsten av en siffra i en sekvens
Låt oss titta på ett exempel. Det slumpmässiga talet 0,2463389991 består av siffrorna 2463389991 och talet 0,5467766618 består av siffrorna 5467766618. Kombinerar vi siffrornas sekvenser, har vi: 246338697966418.
Det är tydligt att den teoretiska sannolikheten sid i nedfall i-th siffran (från 0 till 9) är 0,1.
2) Kontrollera utseendet på serier med identiska nummer
Låt oss beteckna med n L antal serier av på varandra följande siffror av längd L... Allt måste kontrolleras L från 1 till m, var mÄr ett användarspecificerat nummer: det maximala antalet identiska siffror i en serie.
I exemplet "24633899915467766618" hittades 2 serier av längden 2 (33 och 77), dvs. n 2 = 2 och 2 serie 3 lång (999 och 666), det vill säga n 3 = 2 .
Sannolikheten för förekomsten av en serie med en längd på Lär lika med: sid L= 9 10 - L (teoretisk). Det vill säga, sannolikheten för en serie med ett tecken lång är: sid 1 = 0,9 (teoretiskt). Sannolikheten för en serie med två tecken långa är: sid 2 = 0,09 (teoretiskt). Sannolikheten för en rad med tre tecken lång är: sid 3 = 0,009 (teoretiskt).
Till exempel är sannolikheten för en serie på ett tecken lång sid L= 0,9, eftersom det bara kan finnas ett tecken av 10, och det finns 9 tecken totalt (noll räknas inte). Och sannolikheten för att två identiska symboler "XX" kommer att förekomma i en rad är 0,1 · 0,1 · 9, det vill säga sannolikheten för 0,1 att symbolen "X" kommer att dyka upp i den första positionen multipliceras med sannolikheten 0,1 att samma symbolen kommer att visas i den andra positionen "X" och multiplicerad med antalet sådana kombinationer 9.
Frekvensen för seriens utseende beräknas enligt den tidigare analyserade "chi-kvadrat"-formeln med hjälp av värdena sid L .
Notera: generatorn kan kontrolleras många gånger, men kontrollerna är inte kompletta och garanterar inte att generatorn producerar slumpmässiga siffror. Till exempel kommer en generator som utfärdar sekvensen 12345678912345 ... att anses vara idealisk under kontroller, vilket uppenbarligen inte är helt sant.
Avslutningsvis noterar vi att det tredje kapitlet i Donald E. Knuths bok "Konsten att programmera" (volym 2) är helt ägnat åt studiet av slumptal. Den utforskar olika metoder för att generera slumptal, statistiska kriterier för slumpmässighet och omvandling av enhetligt fördelade slumptal till andra typer av slumpvariabler. Mer än tvåhundra sidor har ägnats åt presentationen av detta material.
Få och konvertera slumptal.
Det finns två huvudsakliga sätt att få slumptal:
1) Slumptal genereras av en speciell elektronisk bilaga (slumptalsgenerator) installerad på en dator. Implementeringen av denna metod kräver nästan inga ytterligare operationer, förutom åtkomst av slumptalsgeneratorn.
2) Algoritmisk metod - baserad på bildandet av slumptal i själva maskinen med hjälp av ett speciellt program. Nackdelen med denna metod är den extra förbrukningen av datortid, eftersom maskinen i detta fall utför själva den elektroniska enhetens operationer.
Programmet för att generera slumptal med en given distributionslag kan vara krångligt. Därför erhålls slumptal med en given fördelningslag vanligtvis inte direkt, utan genom att transformera slumptal som har någon form av standardfördelning. Ofta är en sådan standardfördelning en enhetlig fördelning (lätt att erhålla och bekvämlighet för omvandling till andra lagar).
Det är mest lönsamt att få fram slumptal med en enhetlig lag med hjälp av en elektronisk bilaga som befriar datorn från extra kostnader för datortid. Att få en rent enhetlig fördelning på en dator är omöjligt på grund av det begränsade utloppsnätet. Därför, istället för en kontinuerlig samling av siffror på intervallet (0, 1), en diskret samling av 2 n siffror, var n- bitbredd på maskinordet.
Fördelningslagen för en sådan befolkning kallas kvasi-uniform ... Vid n³20 blir skillnaderna mellan enhetliga och kvasiuniforma lagar obetydliga.
För att få kvasi-enhetliga slumptal används två metoder:
1) generering av slumptal med hjälp av en elektronisk anordning genom att simulera några slumpmässiga processer;
2) erhållande av pseudoslumptal med hjälp av speciella algoritmer.
Att motta n-siffrigt binärt slumptal enligt den första metoden, modelleras en sekvens av oberoende slumpvariabler z i, med värdet 0 eller 1. den resulterande sekvensen av 0 och 1, om vi betraktar det som ett bråktal, och är ett slumpmässigt värde av en kvasi-likformig fördelning på intervallet (0, 1). Hårdvarumetoderna för att få dessa siffror skiljer sig endast i sättet att få implementeringen z i.
En av metoderna bygger på att man räknar antalet radioaktiva partiklar under en viss tidsperiod. Dt om antalet partiklar för Dtäven då z i=1 , och om det är udda, då z i=0 .
En annan metod använder bullereffekten från ett vakuumrör. Fastställande av värdet på brusspänningen vid vissa tidpunkter t i, får vi värdena för oberoende slumpvariabler U (t i), dvs. spänning (Volt).
Magnituden z i bestäms i lag:
var a- något värde på tröskelspänningen.
Magnituden a vanligtvis valt från villkoret:
Nackdelen med hårdvarumetoden är att den inte tillåter användning av dubbelkörningsmetoden för att styra driften av algoritmen för att lösa ett problem, eftersom samma slumptal inte kan erhållas under en upprepad körning.
Pseudo-slumpmässigt kallas siffror som bildas på en dator med hjälp av speciella program på ett återkommande sätt: varje slumptal erhålls från det föregående med hjälp av speciella transformationer.
Den enklaste av dessa transformationer är följande. Låt det bli några n- bit binärt tal från intervallet nÎ (0, 1). Låt oss göra det, så kommer vi redan 2 n bitnummer. Låt oss lyfta fram genomsnittet n utsläpp. Erhållen på detta sätt nÄr ett bitnummer och blir det nya värdet på slumptalet. Vi kvadrerar det igen osv. Denna sekvens är pseudo-slumpmässig, eftersom ur en teoretisk synvinkel är det ingen tillfällighet.
Nackdelen med återkommande algoritmer är att sekvenser av slumpmässiga tal kan degenerera (till exempel får vi bara nollsekvensen eller en sekvens av ettor, eller så kan periodicitet dyka upp).
 Nya regler för personlig fastighetsskatt
Nya regler för personlig fastighetsskatt Funktioner av försäljningen av en lägenhet med olaglig ombyggnad
Funktioner av försäljningen av en lägenhet med olaglig ombyggnad Regler och tillvägagångssätt för tentamen
Regler och tillvägagångssätt för tentamen