بدون پنجره تولید کننده اعداد تصادفی بیولوژیکی. حسگرهای اعداد تصادفی و شبه تصادفی GPS در رمزنگاری
سه روش اساساً متفاوت برای بدست آوردن اعداد به صورت تصادفی وجود دارد: فیزیکی، جدولی و الگوریتمی.
اعتقاد بر این است که اولین تلاش برای ایجاد یک مولد اعداد تصادفی فیزیکی به 3500 سال قبل از میلاد برمی گردد. و با بازی تخته ای senet، یک سرگرمی سکولار مصر باستان مرتبط است. با توجه به بازسازی های مدرن قوانین بازی، برای تعیین تعداد امتیازات هر بازیکن و ترتیب حرکات در این بازی، از چهار چوب تخت استفاده شد که یک طرف آن سفید و دیگری سیاه بود. چوب ها همزمان پرتاب می شدند و بسته به ترکیب رنگ هایی که می افتاد، امکانات اضافی بازیکنان مشخص می شد. در آغاز قرن XX. دنباله ای از اعداد تصادفی به صورت دستی شبیه سازی شد - با پرتاب یک سکه یا یک تاس، قرار دادن کارت های بازی، رولت، استخراج توپ از یک کوزه و غیره. حسگرهای فیزیکی (سخت افزاری) مدرن دستگاه های خاصی هستند که اعداد تصادفی را بر اساس تبدیل نویز تصادفی با منشاء طبیعی یا مصنوعی تولید می کنند (نویز حرارتی، اثر شات در لوله های الکترونی، واپاشی رادیواکتیو و غیره). مثلا ماشین ERNIE 4 (تجهیزات نشانگر اعداد تصادفی الکترونیکی),
- 1 گاهی اوقات، اگرچه به ندرت، توزیع ارائه شده توسط جدول 0 1 ... 8 9 استاندارد در نظر گرفته می شود.
- 0.1 0.1 ... 0.1 0.1/ که اعداد برنده در قرعه کشی ماهیانه بریتانیا را مشخص می کند، از نویز حرارتی ترانزیستورها به عنوان منبع متغیرهای تصادفی استفاده می کند. روش فیزیکی بدست آوردن دنباله ای از اعداد تصادفی دارای ویژگی هایی است که برای یک مدل شبیه سازی معایبی است. اینها، اول از همه، نیاز به اقدامات ویژه برای اطمینان از پایداری منبع سیگنال تبدیل شده به اعداد تصادفی و عدم امکان بازتولید توالی حاصل از اعداد تصادفی را شامل می شود.
جداول اعداد تصادفی خالی از این کاستی ها هستند. اجازه دهید توضیح دهیم که منظور از جدول اعداد تصادفی چیست. فرض کنید ما انجام داده ایم نآزمایشهای مستقل، که در نتیجه آن اعداد تصادفی a، a 2، osdg را دریافت کردیم. با ثبت این اعداد (به ترتیب شکل ظاهری و به صورت جدول مستطیل شکل) به اصطلاح جدول اعداد تصادفی به دست می آید. به روش زیر استفاده می شود. در طول محاسبات، ممکن است به یک رقم تصادفی یا یک عدد تصادفی نیاز داشته باشیم. اگر یک عدد تصادفی مورد نیاز است، میتوانیم هر عددی را از این جدول بگیریم. همین امر در مورد یک عدد تصادفی عدد صحیح صدق می کند - برای هر رقم، می توانید هر رقمی را انتخاب کنید. اگر به یک عدد تصادفی 0 k از ارقام بعدی c، a 2، os / نیاز داشته باشیم و فرض کنیم که 8 = (Xo ^. -. o ^. علاوه بر این، در مورد یک جدول "ایده آل" از ارقام تصادفی، شما می توانید اعداد را از آن به طور تصادفی انتخاب کنید، این امکان را به صورت ردیفی دارد، می توانید از هر الگوریتم انتخابی استفاده کنید که به مقادیر اعداد جدول بستگی ندارد، از هر جایی در جدول شروع کنید، در هر جهت بخوانید. .
اولین جداول اعداد تصادفی با استفاده از رولت به دست آمد. این گونه جداول چندین بار در قالب کتاب منتشر شد. یکی از مشهورترین جداول، که در سال 1927 منتشر شد، حاوی بیش از 40000 رقم تصادفی "به طور تصادفی برگرفته از گزارش های سرشماری" بود.
مرجع تاریخ
لئونارد تیپت (لئونارد هنری کالب تیپت)، 1902-1985) - آماردان انگلیسی، شاگرد K. Pearson و R. Fisher. در سال 1965-1966 - رئیس انجمن سلطنتی آمار. برخی از نتایج مهم در نظریه مقادیر افراطی با نام او مرتبط است، به عنوان مثال، توزیع فیشر-تیپت و قضیه فیشر-تیپت-گندنکو.
بعداً دستگاههای ویژهای ساخته شد که به صورت مکانیکی اعداد تصادفی تولید میکنند. اولین چنین ماشینی در سال 1939 توسط M. J. Kendall و B. Babington-Smith برای ایجاد جداول حاوی 100000 رقم تصادفی استفاده شد. در سال 1955 شرکت شرکت رندجداول معروفی را با یک میلیون رقم تصادفی منتشر کرد که توسط ماشین دیگری از این نوع به دست آمده است. کاربرد عملی جداول اعداد تصادفی در حال حاضر، به عنوان یک قاعده، محدود به کارهایی است که از روش های انتخاب تصادفی استفاده می کنند.
نمونه ها، به عنوان مثال، در مطالعات جامعه شناختی یا هنگام انجام کنترل پذیرش آماری کیفیت محصولات قطعه برای اهداف مختلف.
جالبه
در روسیه، GOST 18321-73 (ST SEV 1934-79) وجود دارد که قوانین انتخاب واحدهای محصول در یک نمونه را هنگام انجام کنترل کیفیت پذیرش آماری، روش های آماری برای تجزیه و تحلیل و تنظیم فرآیندهای تکنولوژیکی برای انواع محصولات قطعه تعیین می کند. برای مقاصد صنعتی و کالاهای مصرفی. به طور خاص، بیان می کند که هنگام انتخاب واحدهای تولید در نمونه، "جدول اعداد تصادفی مطابق ST SEV 546-77 استفاده می شود."
درخواست مجدد همه اعداد به راحتی تکثیر می شوند. و عرضه اعداد در چنین دنباله ای محدود است. با این حال، دنباله ای از اعداد شبه تصادفی یک مزیت آشکار نسبت به جدول دارد: فرمول های ساده ای برای محاسبه یک عدد شبه تصادفی وجود دارد، در حالی که فقط 3-5 دستور برای به دست آوردن هر عدد صرف می شود، و برنامه محاسبه فقط تعداد کمی را اشغال می کند. سلول ها در درایو
الگوریتمهای زیادی برای بدست آوردن دنبالهای از اعداد شبه تصادفی وجود دارد؛ پیادهسازی این الگوریتمها، که حسگر (مولدکننده) اعداد شبه تصادفی نامیده میشوند، با جزئیات در ادبیات خاصی شرح داده شدهاند. اجازه دهید برخی از شناخته شده ترین الگوریتم ها را نشان دهیم.
- تیپت ال. اعداد نمونه گیری تصادفی. لندن: انتشارات دانشگاه کمبریج، 1927.
- رجوع کنید به: Knut D. E. The Art of Programming. ویرایش 3 M.: Williams, 2000. T. 2. Ch. 3. اعداد تصادفی.
PRNG های قطعی
هیچ الگوریتم قطعی نمی تواند اعداد کاملا تصادفی تولید کند، فقط می تواند برخی از ویژگی های اعداد تصادفی را تقریب بزند. همانطور که جان فون نویمان گفت: هر کس در روش های حسابی برای بدست آوردن اعداد تصادفی ضعف داشته باشد بدون شک گناهکار است».
هر PRNG با منابع محدود دیر یا زود در چرخه های مختلف قرار می گیرد - شروع به تکرار همان دنباله اعداد می کند. طول چرخه های PRNG به خود مولد بستگی دارد و به طور متوسط حدود 2 n/2 است، که در آن n اندازه حالت داخلی در بیت است، اگرچه ژنراتورهای خطی متجانس و LFSR حداکثر چرخه های مرتبه 2 n را دارند. اگر یک PRNG بتواند به چرخه هایی که خیلی کوتاه هستند همگرا شود، آن PRNG قابل پیش بینی و غیرقابل استفاده می شود.
اکثر ژنراتورهای ساده حسابی، اگرچه سریع هستند، اما از کاستی های جدی زیادی رنج می برند:
- دوره/دوره های خیلی کوتاه.
- مقادیر متوالی مستقل نیستند.
- برخی بیت ها نسبت به بقیه "کمتر تصادفی" هستند.
- توزیع تک بعدی غیر یکنواخت.
- برگشت پذیری
به طور خاص، الگوریتم مین فریم بسیار ضعیف بود، که باعث شک و تردید در مورد قابلیت اطمینان نتایج بسیاری از مطالعاتی شد که از این الگوریتم استفاده کردند.
PRNG با منبع آنتروپی یا RNG
در کنار نیاز به تولید توالی هایی از اعداد تصادفی که به راحتی قابل تکرار هستند، نیاز به تولید اعداد کاملاً غیرقابل پیش بینی یا کاملاً تصادفی نیز وجود دارد. چنین ژنراتورهایی نامیده می شوند مولد اعداد تصادفی(RNG - eng. مولد اعداد تصادفی، RNG). از آنجایی که چنین ژنراتورهایی اغلب برای تولید کلیدهای متقارن و نامتقارن منحصر به فرد برای رمزگذاری استفاده میشوند، اغلب از ترکیبی از یک PRNG قوی رمزنگاری و یک منبع آنتروپی خارجی ساخته میشوند (و این ترکیب اکنون معمولاً به عنوان RNG شناخته میشود).
تقریباً تمام تولیدکنندگان بزرگ ریزتراشه، RNG های سخت افزاری را با منابع مختلف آنتروپی، با استفاده از روش های مختلف برای پاک کردن آنها از قابلیت پیش بینی اجتناب ناپذیر، تامین می کنند. با این حال، در حال حاضر، سرعت جمع آوری اعداد تصادفی توسط همه ریزتراشه های موجود (چند هزار بیت در ثانیه) با سرعت پردازنده های مدرن مطابقت ندارد.
در رایانههای شخصی، نویسندگان نرمافزار RNG از منابع آنتروپی بسیار سریعتری مانند نویز کارت صدا یا شمارنده ساعت پردازنده استفاده میکنند. قبل از توانایی خواندن مقادیر شمارنده ساعت، مجموعه آنتروپی آسیب پذیرترین نقطه RNG بود. این مشکل هنوز در بسیاری از دستگاهها (مثلاً کارتهای هوشمند) که در نتیجه آسیبپذیر هستند، به طور کامل حل نشده است. بسیاری از RNGها هنوز از روشهای جمعآوری آنتروپی سنتی (منسوخ) مانند اندازهگیری پاسخ کاربر (حرکت ماوس و غیره) استفاده میکنند، به عنوان مثال، یا تعاملات بین رشتهها، به عنوان مثال، در جاوا امن تصادفی.
نمونه هایی از منابع RNG و آنتروپی
چند نمونه از RNG با منابع آنتروپی و مولدهای آنها:
| منبع آنتروپی | PRNG | مزایای | ایرادات | |
|---|---|---|---|---|
| /dev/random در لینوکس | شمارشگر ساعت پردازنده، با این حال، فقط در هنگام وقفه های سخت افزاری جمع آوری می شود | LFSR، با خروجی هش شده از طریق | برای مدت طولانی "گرم می شود"، می تواند برای مدت طولانی "گیر کند" یا مانند PRNG کار می کند ( /dev/urandom) | |
| بومادرانتوسط بروس اشنایر | روشهای سنتی (منسوخ) | AES-256 و | طراحی انعطاف پذیر مقاوم در برابر رمزنگاری | برای مدت طولانی "گرم می شود"، حالت داخلی بسیار کوچک، بیش از حد به قدرت رمزنگاری الگوریتم های انتخاب شده بستگی دارد، کند، فقط برای تولید کلید قابل اجرا است. |
| ژنراتور لئونید یوریف | نویز کارت صدا | ? | احتمالاً منبع خوب و سریع آنتروپی است | هیچ PRNG مستقلی که به عنوان ایمن شناخته شده است، منحصراً در ویندوز موجود نیست |
| مایکروسافت | ساخته شده در ویندوز، گیر نمی کند | وضعیت داخلی کوچک، آسان برای پیش بینی | ||
| ارتباط بین رشته ها | در جاوا، هنوز گزینه دیگری وجود ندارد، یک حالت داخلی بزرگ | مجموعه آنتروپی آهسته | ||
| آشوب توسط روپتور | شمارنده ساعت پردازنده، به طور مداوم جمع آوری می شود | هش کردن یک حالت داخلی 4096 بیتی بر اساس نسخه غیر خطی ژنراتور Marsaglia | در حالی که سریعترین حالت داخلی بزرگ، "گیر نمیکند" | |
| RRAND توسط Ruptor | شمارشگر سیکل پردازنده | رمزگذاری حالت داخلی با رمز جریان | بسیار سریع، حالت داخلی با اندازه دلخواه با انتخاب، "گیر نمی کند" |
PRNG در رمزنگاری
گونهای از PRNG عبارتند از GPSB (PRBG) - مولد بیتهای شبه تصادفی، و همچنین رمزهای جریانی مختلف. PRNG ها، مانند رمزهای جریان، از یک حالت داخلی (معمولا از 16 بیت تا چند مگابایت اندازه)، یک تابع برای مقداردهی اولیه حالت داخلی با یک کلید یا دانه(انگلیسی) دانهتوابع به روز رسانی حالت داخلی و توابع خروجی. PRNG ها به دو دسته محاسباتی ساده، رمزنگاری شکسته و قوی رمزنگاری تقسیم می شوند. هدف کلی آنها تولید دنباله هایی از اعداد است که با روش های محاسباتی نمی توان آنها را از اعداد تصادفی تشخیص داد.
اگرچه بسیاری از PRNG ها یا رمزهای جریانی قوی اعداد "تصادفی" بیشتری ارائه می دهند، چنین مولدهایی بسیار کندتر از مولدهای محاسباتی معمولی هستند و ممکن است برای هر نوع تحقیقی که نیازمند آزاد بودن پردازنده برای محاسبات مفیدتر باشد، مناسب نباشند.
برای مقاصد نظامی و در میدان، فقط PRNGهای همزمان مخفی مقاوم در برابر رمزنگاری (رمزهای جریانی) استفاده می شود، رمزهای بلوکی استفاده نمی شود. نمونههایی از PRNGهای معروف رمزنگاری قوی عبارتند از ISAAC، SEAL، Snow، الگوریتم نظری بسیار کند Bloom، Bloom و Shub، و همچنین شمارندههایی با توابع هش رمزنگاری یا رمزنگاریهای بلوکی امن بهجای تابع خروجی.
PRNG سخت افزاری
جدا از ژنراتورهای منسوخ و شناخته شده LFSR که به طور گسترده به عنوان PRNG های سخت افزاری در قرن بیستم مورد استفاده قرار می گرفتند، متأسفانه اطلاعات کمی در مورد PRNG های سخت افزاری مدرن (رمزهای جریانی) وجود دارد، زیرا بیشتر آنها برای اهداف نظامی توسعه یافته اند و مخفی نگه داشته می شوند. . تقریباً تمام سخت افزارهای تجاری موجود PRNG ثبت اختراع هستند و همچنین مخفی نگه داشته می شوند. PRNG های سخت افزاری با الزامات سختگیرانه برای مصرف حافظه (اغلب استفاده از حافظه ممنوع است)، سرعت (1-2 چرخه) و مساحت (چند صد FPGA - یا
به دلیل فقدان PRNG های سخت افزاری خوب، سازندگان مجبور به استفاده از رمزهای بلاک بسیار کندتر اما به طور گسترده ای شناخته شده در دسترس هستند (Computer Review No. 29 (2003)
اولین الگوریتم برای بدست آوردن اعداد شبه تصادفی توسط J. Neumann ارائه شد. به آن روش مربع میانی می گویند.
بگذارید یک عدد R 4 رقمی داده شود 0 =0.9876. بیایید آن را مربع کنیم. یک عدد 8 رقمی R بگیرید 0 2 =0.97535376. از این عدد 4 رقم وسط انتخاب می کنیم و R می گذاریم 1 =0.5353. سپس دوباره آن را مربع می کنیم و 4 رقم وسط را از آن استخراج می کنیم. بیایید R را بگیریم 2 و غیره. این الگوریتم خود را توجیه نکرده است. معلوم شد که مقادیر کوچک R بیش از حد لازم است من .
با این حال، بررسی کیفیت این ژنراتور با گروه انتخاب رقمی R به سمت راست مورد توجه است. من 2 :
که در آن a حداکثر مقدار کسری برای یک کامپیوتر معین است (به عنوان مثال، a = 8).
b-تعداد ارقام اعشاری در عددR من(مثلاً 5).
INT(A) قسمت صحیح عدد است.
برای a=8,b=5,R 0 \u003d 0.51111111 در PC ZX-Spectrum، حدود 1200 عدد غیر تکراری به دست می آید.
ورزش: مطالعه باید با متغیرهای a،b،R انجام شود 0 . با چه مقادیری a,b,R بیابید 0 بزرگترین طول L دنباله ای از اعداد غیر تکراری با پارامترهای تصادفی "خوب" به دست می آید. تعیین کنید که آیا مقدار R تأثیر می گذارد یا خیر 0 در مورد کیفیت سنسور اگر چنین شد، محدوده مقادیر "قابل قبول" پارامتر R را تعیین کنید 0 . نتایج آزمایش نوع بهینه مقادیر a,b,R را ارائه دهید 0 .
الگوریتم های ضربی سنسور شماره 2: ژنراتور همگام خطی Lemaire 1951.
جایی که U من,M,Cip اعداد صحیح هستند.
AmodB باقیمانده تقسیم عدد صحیح A بر B است،
A mod B=A-B*INT(A/B)
دنباله تولید شده دارای یک چرخه تکراری است که از pnumber تجاوز نمی کند.
حداکثر دوره در C0 به دست می آید، اما چنین مولد نتایج تصادفی ضعیفی می دهد.
وقتی مولدهای C=0 را ضربی می نامند. آنها بهترین پارامترهای تصادفی را دارند. فرمول های استفاده از آنها را روش کسر نیز می نامند.
محبوب ترین روش برای به دست آوردن اعداد شبه تصادفی، روش باقیمانده ها طبق فرمول زیر است:
جایی که U من,M,p-اعداد صحیح, 0
اگر U را انتخاب کنید 0 و M طوری که برای R 0 =U 0 /pنتیجه یک کسر غیر قابل کاهش است و pM coprime و سپس allR را می گیریم منکسرهای تقلیل ناپذیر به شکل R خواهند بود من=U من/پ.
بیایید بزرگترین (اما نه بیشتر از p) طول یک دنباله اعداد غیر تکراری را بدست آوریم. ارزش U 0 و M برای انتخاب از اعداد اول راحت است.
ورزش: کاوش در whatU 0 و M طول دنباله اعداد غیر تکراری حداقل 10000 با پارامترهای تصادفی "خوب" خواهد بود. تعیین کنید که آیا مقدار R تأثیر می گذارد یا خیر 0 با Mip=const بر روی ویژگی های آماری سنسور. اگر چنین شد، محدوده مقادیر مجاز U را تعیین کنید 0 . نتایج آزمایش ژنراتور را برای مقادیر بهینه p، Mi و U ارائه دهید 0 .
سنسور شماره 3: اصلاح Korobov.

که در آن p یک عدد اول بزرگ است، مانند 2027، 5087، ...
M یک عدد صحیح است که شرایط زیر را دارد:

n یک عدد صحیح است. آن ها M نزدیک به p/2 را از مجموعه اعداد M=p– 3 n انتخاب کنید.
به عنوان مثال، برای p=5087، n=7 را می گیریم. زیرا 3 7 =2187 و 3 8 =6561 بیشتر از p خواهد بود. پس: M=5087-2187=2900.
ما اعداد U را دریافت می کنیم مندر بازه = و اعداد R مندر بازه (0،1).
ورزش: Mp را انتخاب کنید که در آن بهترین پارامترهای آماری سنسور و بزرگترین طول L بدست می آید. دریابید که آیا مقدار R تأثیر می گذارد یا خیر 0 بر روی ویژگی های تصادفی سنسور و در صورت تاثیر آن، محدوده مقادیر مجاز R را تعیین کنید 0 . نتایج تست حسگر را برای مقادیر بهینه M، p و R ارائه دهید 0 .
توجه داشته باشید که در حالت ایده آل، منحنی چگالی توزیع اعداد تصادفی مانند شکل نشان داده شده در شکل 1 خواهد بود. 22.3. یعنی در حالت ایده آل، تعداد نقاط یکسانی در هر بازه قرار می گیرد: ن من = ن/ک ، جایی که نتعداد کل امتیازات است، ک- تعداد فواصل، من= 1، …، ک .
تولید شده توسط یک ژنراتور ایده آل از لحاظ نظری
لازم به یادآوری است که تولید یک عدد تصادفی دلخواه شامل دو مرحله است:
- ایجاد یک عدد تصادفی نرمال شده (یعنی توزیع یکنواخت از 0 تا 1).
- تبدیل اعداد تصادفی نرمال شده r منبه اعداد تصادفی ایکس من، که بر اساس قانون توزیع (خودسرانه) مورد نیاز کاربر یا در بازه زمانی مورد نیاز توزیع می شوند.
مولدهای اعداد تصادفی با توجه به روش به دست آوردن اعداد به موارد زیر تقسیم می شوند:
- فیزیکی؛
- جدولی
- الگوریتمی
RNG های فیزیکی
نمونه هایی از RNG های فیزیکی عبارتند از: یک سکه ("عقاب" - 1، "دم" - 0). تاس؛ یک درام با یک فلش به بخش هایی با اعداد تقسیم شده است. مولد نویز سخت افزاری (GS)، که به عنوان یک دستگاه حرارتی پر سر و صدا، به عنوان مثال، یک ترانزیستور استفاده می شود (شکل 22.4-22.5).
| وظیفه "تولید اعداد تصادفی با استفاده از یک سکه" | |
|
با استفاده از یک سکه یک عدد تصادفی 3 رقمی ایجاد کنید که به طور یکنواخت بین 0 و 1 توزیع شده است. دقت سه رقم اعشار است. |
|
اولین راه حل مشکل
فاصله ای از 0 تا 1 رسم کنید. با خواندن اعداد به ترتیب از چپ به راست، فاصله را به نصف تقسیم کنید و هر بار یکی از قسمت های فاصله بعدی را انتخاب کنید (اگر 0 افتاد، چپ، اگر 1 افتاد، سپس درست). بنابراین، شما می توانید به هر نقطه در بازه زمانی، دلخواه و دقیق برسید. بنابراین، 1 : فاصله به نصف تقسیم می شود - و ، - نیمه سمت راست انتخاب می شود، فاصله باریک می شود: . شماره بعدی 0 : فاصله به نصف تقسیم می شود - و - نیمه چپ انتخاب می شود، فاصله باریک می شود: . شماره بعدی 0 : فاصله به نصف تقسیم می شود - و - نیمه چپ انتخاب می شود، فاصله باریک می شود: . شماره بعدی 1 : فاصله به نصف تقسیم می شود - و ، - نیمه سمت راست انتخاب می شود، فاصله باریک می شود: . با توجه به شرایط دقت مسئله، راه حل پیدا می شود: هر عددی از بازه است، برای مثال 0.625. در اصل، اگر به شدت نزدیک شویم، تقسیم فواصل باید تا مرزهای چپ و راست بازه پیدا شده COINCIDENT با یکدیگر تا داخل رقم سوم اعشار ادامه یابد. یعنی از نظر دقت عدد تولید شده دیگر از فاصله زمانی که در آن قرار دارد از هیچ عددی قابل تشخیص نخواهد بود.
راه دوم برای حل مشکل
|
RNG جدولی
RNG جدولی به عنوان منبعی از اعداد تصادفی از جداول کامپایل شده مخصوصی استفاده می کند که حاوی غیر همبستگی تایید شده است، یعنی اعدادی که به هیچ وجه به یکدیگر وابسته نیستند. روی میز. 22.1 قطعه کوچکی از چنین جدولی را نشان می دهد. با قدم زدن روی جدول از چپ به راست از بالا به پایین، می توانید اعداد تصادفی را به طور مساوی از 0 تا 1 با تعداد ارقام اعشاری مورد نظر توزیع کنید (در مثال ما برای هر عدد از سه رقم اعشار استفاده می کنیم). از آنجایی که اعداد جدول به یکدیگر وابسته نیستند، جدول را می توان به روش های مختلفی پیمود، مثلاً از بالا به پایین، یا از راست به چپ، یا مثلاً می توانید اعدادی را انتخاب کنید که در موقعیت های زوج هستند.
| جدول 22.1. اعداد تصادفی به طور مساوی از 0 تا 1 اعداد تصادفی توزیع شده است |
||||||||||||||||||||||||||||||||||||||||||||
| اعداد تصادفی | یکنواخت توضیع شده 0 تا 1 اعداد تصادفی |
|||||||
| 9 | 2 | 9 | 2 | 0 | 4 | 2 | 6 | 0.929 |
| 9 | 5 | 7 | 3 | 4 | 9 | 0 | 3 | 0.204 |
| 5 | 9 | 1 | 6 | 6 | 5 | 7 | 6 | 0.269 |
مزیت این روش این است که اعداد واقعاً تصادفی را ارائه می دهد، زیرا جدول حاوی اعداد غیر همبسته تأیید شده است. معایب روش: حافظه زیادی برای ذخیره تعداد زیادی ارقام مورد نیاز است. مشکلات بزرگ در تولید و بررسی چنین جداول، تکرارها در هنگام استفاده از جدول دیگر تصادفی بودن دنباله عددی و در نتیجه قابل اعتماد بودن نتیجه را تضمین نمی کند.
جدولی حاوی 500 عدد تأیید شده کاملاً تصادفی وجود دارد (برگرفته از کتاب I. G. Venetsky, V. I. Venetskaya "مفاهیم و فرمول های اساسی ریاضی و آماری در تحلیل اقتصادی").
RNG الگوریتمی
اعداد تولید شده با استفاده از این RNG ها همیشه شبه تصادفی (یا شبه تصادفی) هستند، یعنی هر عدد تولید شده بعدی به عدد قبلی بستگی دارد:
r من + 1 = f(r من) .
دنباله هایی که از چنین اعدادی تشکیل شده اند حلقه ها را تشکیل می دهند، یعنی لزوماً یک چرخه وجود دارد که بی نهایت بار تکرار می شود. به چرخه های تکراری دوره می گویند.
مزیت داده های RNG سرعت است. ژنراتورها عملاً به منابع حافظه نیاز ندارند، آنها فشرده هستند. معایب: اعداد را نمی توان به طور کامل تصادفی نامید، زیرا بین آنها وابستگی وجود دارد و همچنین وجود نقطه در دنباله اعداد شبه تصادفی وجود دارد.
چندین روش الگوریتمی برای بدست آوردن RNG در نظر بگیرید:
- روش مربع های میانی؛
- روش محصولات میانی؛
- روش اختلاط؛
- روش همگرای خطی
روش مربع میانگین
یک عدد چهار رقمی وجود دارد آر 0 . این عدد مربع شده و وارد می شود آریکی . داره میاد از آر 1 وسط (چهار رقم وسط) گرفته می شود - یک عدد تصادفی جدید - و در آن نوشته می شود آر 0 . سپس این روش تکرار می شود (شکل 22.6 را ببینید). توجه داشته باشید که در واقع به عنوان یک عدد تصادفی باید not را گرفت قیج، آ 0.ghij- با یک عدد صفر و یک اعشار به سمت چپ اختصاص داده شده است. این واقعیت در شکل 1 منعکس شده است. 22.6 و در شکل های مشابه بعدی.
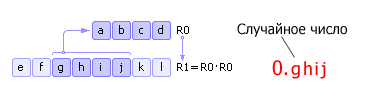 |
معایب روش: 1) اگر در برخی از تکرار تعداد آر 0 صفر می شود، سپس ژنراتور منحط می شود، بنابراین انتخاب صحیح مقدار اولیه مهم است آر 0; 2) ژنراتور دنباله را از طریق تکرار خواهد کرد م nمراحل (در بهترین حالت)، که در آن n- ظرفیت رقمی شماره آر 0 , مپایه سیستم اعداد است.
برای مثال در شکل. 22.6 : اگر شماره آر 0 در سیستم اعداد باینری نشان داده می شود، سپس دنباله اعداد شبه تصادفی پس از 2 4 = 16 مرحله تکرار می شود. توجه داشته باشید که اگر شماره اولیه ناموفق انتخاب شود، تکرار دنباله ممکن است حتی زودتر رخ دهد.
روشی که در بالا توضیح داده شد توسط جان فون نویمان پیشنهاد شد و به سال 1946 باز می گردد. از آنجایی که این روش غیرقابل اعتماد بود، به سرعت کنار گذاشته شد.
روش محصولات متوسط
عدد آر 0 ضرب در آر 1، از نتیجه آر 2 وسط حذف شده است آر 2 * (این یک عدد تصادفی دیگر است) و ضرب در آریکی . بر اساس این طرح، تمام اعداد تصادفی بعدی محاسبه می شوند (شکل 22.7 را ببینید).
 |
روش اختلاط
روش زدن از عملیات برای چرخش محتویات یک سلول به چپ و راست استفاده می کند. ایده روش به شرح زیر است. اجازه دهید سلول شماره اولیه را ذخیره کند آر 0 . با انتقال چرخه ای محتویات سلول به چپ به اندازه 1/4 طول سلول، عدد جدیدی به دست می آید. آر 0*. به طور مشابه، با جابجایی چرخه ای محتویات یک سلول آر 0 به سمت راست در 1/4 طول سلول، عدد دوم را بدست می آوریم آر 0**. مجموع اعداد آر 0 * و آر 0** یک عدد تصادفی جدید می دهد آریکی . به علاوه آر 1 وارد شده است آر 0، و کل دنباله عملیات تکرار می شود (شکل 22.8 را ببینید).
 |
توجه داشته باشید که عدد حاصل از جمع آر 0 * و آر 0 **، ممکن است به طور کامل در سلول قرار نگیرد آریکی . در این حالت، ارقام اضافی باید از شماره دریافتی حذف شوند. اجازه دهید این را برای شکل توضیح دهیم. 22.8، که در آن تمام سلول ها با هشت رقم باینری نمایش داده می شوند. اجازه دهید آر 0 * = 10010001 2 = 145 10 , آر 0 ** = 10100001 2 = 161 10 ، سپس آر 0 * + آر 0 ** = 100110010 2 = 306 10 . همانطور که می بینید، عدد 306 9 رقم را اشغال می کند (در سیستم اعداد باینری) و سلول آر 1 (و همچنین آر 0 ) می تواند حداکثر 8 بیت را در خود جای دهد. بنابراین، قبل از وارد کردن مقدار در آر 1 لازم است یک بیت "اضافی"، سمت چپ را از عدد 306 حذف کنید، در نتیجه آر 1 دیگر 306 نخواهد رفت، بلکه 00110010 2 = 50 10 خواهد بود. همچنین توجه داشته باشید که در زبانهایی مانند پاسکال، «قطع کردن» بیتهای اضافی هنگام سرریز شدن سلول به طور خودکار مطابق با نوع متغیر داده شده انجام میشود.
روش همگرای خطی
روش همخوانی خطی یکی از سادهترین و پرکاربردترین روشهایی است که اعداد تصادفی را شبیهسازی میکند. این روش از mod( ایکس, y) که پس از تقسیم آرگومان اول بر آرگومان دوم، باقیمانده را برمی گرداند. هر عدد تصادفی بعدی بر اساس عدد تصادفی قبلی با استفاده از فرمول زیر محاسبه می شود:
r من+ 1 = mod( ک · r من + ب, م) .
دنباله اعداد تصادفی به دست آمده با استفاده از این فرمول نامیده می شود دنباله همگام خطی. بسیاری از نویسندگان به دنباله همگام خطی به عنوان ب = 0 روش ضربی همگام، و وقتی که ب ≠ 0 روش همگام مختلط.
برای یک ژنراتور با کیفیت بالا، لازم است ضرایب مناسب انتخاب شود. لازم است که شماره مبسیار بزرگ بود زیرا دوره نمی تواند بیشتر باشد معناصر. از سوی دیگر، تقسیم مورد استفاده در این روش یک عملیات نسبتا کند است، بنابراین برای یک کامپیوتر باینری، انتخاب منطقی خواهد بود. م = 2 ن، زیرا در این حالت یافتن باقی مانده تقسیم در داخل کامپیوتر به عملیات منطقی باینری "AND" کاهش می یابد. انتخاب بزرگترین عدد اول نیز معمول است م، کمتر از 2 ن: در ادبیات خاص ثابت شده است که در این مورد کمترین ارقام عدد تصادفی حاصل r من+ 1 به اندازه ی بزرگترها تصادفی رفتار می کنند، که تأثیر مثبتی روی کل دنباله اعداد تصادفی به عنوان یک کل دارد. یک مثال یکی از اعداد مرسن، برابر با 2 31 - 1، و بنابراین، م= 2 31 - 1.
یکی از ملزومات دنباله های متجانس خطی طولانی ترین دوره ممکن است. طول دوره بستگی به مقادیر دارد م , کو ب. قضیه ای که در زیر ارائه می کنیم به ما امکان می دهد تعیین کنیم که آیا امکان دستیابی به دوره ای با حداکثر طول برای مقادیر خاص وجود دارد یا خیر م , کو ب .
قضیه. دنباله همگام خطی که با اعداد تعریف می شود م , ک , بو r 0، دارای یک دوره طولانی است ماگر و تنها اگر:
- شماره بو م coprime;
- ک- 1 بار پبرای هر ساده پ، که مقسوم علیه است م ;
- ک- 1 مضرب 4 است اگر ممضرب 4
در نهایت، اجازه دهید با چند مثال از استفاده از روش همگرایانه خطی برای تولید اعداد تصادفی نتیجه گیری کنیم.
مشخص شد که یک سری از اعداد شبه تصادفی تولید شده بر اساس داده های مثال 1 هر بار تکرار خواهند شد. م/4 عدد. عدد qقبل از شروع محاسبات به طور خودسرانه تنظیم می شود، با این حال، باید در نظر داشت که این مجموعه تصور تصادفی بودن را در کل ایجاد می کند. ک(و بنابراین q). نتیجه می تواند اندکی بهبود یابد اگر بعجیب و غریب و ک= 1 + 4 q - در این صورت سریال هر بار تکرار خواهد شد مشماره. پس از یک جستجوی طولانی کمحققان بر روی مقادیر 69069 و 71365 مستقر شدند.
مولد اعداد تصادفی با استفاده از داده های مثال 2، اعداد تصادفی غیر تکراری را با دوره 7 میلیون تولید می کند.
یک روش ضربی برای تولید اعداد شبه تصادفی توسط D.H. Lehmer در سال 1949 ارائه شد.
بررسی کیفیت ژنراتور
کیفیت کل سیستم و دقت نتایج به کیفیت RNG بستگی دارد. بنابراین، دنباله تصادفی تولید شده توسط RNG باید تعدادی از معیارها را برآورده کند.
بررسی های انجام شده بر دو نوع است:
- چک برای توزیع یکنواخت؛
- تست استقلال آماری
بررسی توزیع یکنواخت
1) RNG باید نزدیک به مقادیر زیر پارامترهای آماری مشخصه یک قانون تصادفی یکنواخت را ارائه دهد:
2) تست فرکانس
تست فرکانس به شما امکان می دهد دریابید که چند عدد در بازه قرار گرفته اند (متر r σ r ; متر r + σ r) ، یعنی (0.5 - 0.2887؛ 0.5 + 0.2887) یا در نهایت (0.2113; 0.7887). از آنجایی که 0.7887 - 0.2113 = 0.5774، نتیجه می گیریم که در یک RNG خوب، حدود 57.7٪ از تمام اعداد تصادفی که خارج شده اند باید در این بازه قرار گیرند (شکل 22.9 را ببینید).
در صورت بررسی آن برای آزمایش فرکانس
همچنین باید در نظر داشت که تعداد اعداد در بازه (0؛ 0.5) باید تقریباً برابر با تعداد اعداد در بازه (0.5؛ 1) باشد.
3) آزمون کای دو
آزمون کای اسکوئر (x2-test) یکی از بهترین آزمون های آماری شناخته شده است. این روش اصلی مورد استفاده در ترکیب با معیارهای دیگر است. آزمون کای اسکوئر در سال 1900 توسط کارل پیرسون پیشنهاد شد. کار قابل توجه او به عنوان پایه و اساس آمار ریاضی مدرن در نظر گرفته می شود.
برای مورد ما، یک تست مجذور کای به ما این امکان را میدهد که بفهمیم چقدر ایجاد شده توسط ما واقعی RNG نزدیک به مرجع RNG است، یعنی اینکه آیا نیاز توزیع یکنواخت را برآورده می کند یا خیر.
نمودار فرکانس مرجع RNG در شکل نشان داده شده است. 22.10. از آنجایی که قانون توزیع RNG مرجع یکنواخت است، احتمال (تئوری) وجود دارد پ منزدن اعداد در من-امین بازه (مجموع این فواصل ک) برابر است با پ من = 1/ک . و به این ترتیب، در هر یک کفواصل زمانی کاهش خواهد یافت صافبر پ من · ن شماره ( نتعداد کل اعداد تولید شده است).
یک RNG واقعی اعداد توزیع شده را تولید می کند (و نه لزوماً به طور مساوی!) کفواصل و هر بازه شامل خواهد شد n مناعداد (کل n 1 + n 2 + … + n ک = ن ). چگونه میتوانیم تشخیص دهیم که RNG آزمایششده چقدر خوب است و به یک مرجع ببندیم؟ کاملاً منطقی است که مجذورهای تفاوت بین تعداد دریافتی اعداد را در نظر بگیرید n منو "مرجع" پ من · ن . بیایید آنها را جمع کنیم و در نتیجه به دست می آوریم:
χ 2 exp. =( n 1- پیک · ن) 2 + (n 2- پ 2 · ن) 2 + … + ( n ک پ ک · ن) 2 .
از این فرمول نتیجه میشود که هرچه تفاوت در هر یک از عبارتها کوچکتر باشد (و بنابراین مقدار χ2 exp. ) کمتر باشد، قانون توزیع اعداد تصادفی تولید شده توسط یک RNG واقعی قویتر است.
در عبارت قبلی، به هر یک از اصطلاحات یک وزن (برابر با 1) اختصاص داده شده است که در واقع ممکن است درست نباشد; بنابراین برای آماره کای اسکوئر نرمال کردن هر یک ضروری است منترم، تقسیم آن بر پ من · ن :
در نهایت، بیایید عبارت حاصل را فشرده تر بنویسیم و آن را ساده کنیم:
ما مقدار آزمون کای دو را به دست آورده ایم تجربیداده ها.
روی میز. 22.2 داده شده است نظریمقادیر مجذور کای (χ 2 نظریه)، که در آن ν = ن- 1 تعداد درجات آزادی است، پیک سطح اطمینان مشخص شده توسط کاربر است که مشخص می کند RNG چقدر باید الزامات توزیع یکنواخت را برآورده کند، یا پ احتمال این است که مقدار تجربی χ 2 exp. کمتر از نظریه χ 2 جدول بندی شده (نظری) خواهد بود. یا برابر با آن.
| جدول 22.2. چند درصد از توزیع χ2 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| p = 1٪ | p = 5٪ | p = 25٪ | p = 50٪ | p = 75٪ | p = 95٪ | p = 99٪ | |
| ν = 1 | 0.00016 | 0.00393 | 0.1015 | 0.4549 | 1.323 | 3.841 | 6.635 |
| ν = 2 | 0.02010 | 0.1026 | 0.5754 | 1.386 | 2.773 | 5.991 | 9.210 |
| ν = 3 | 0.1148 | 0.3518 | 1.213 | 2.366 | 4.108 | 7.815 | 11.34 |
| ν = 4 | 0.2971 | 0.7107 | 1.923 | 3.357 | 5.385 | 9.488 | 13.28 |
| ν = 5 | 0.5543 | 1.1455 | 2.675 | 4.351 | 6.626 | 11.07 | 15.09 |
| ν = 6 | 0.8721 | 1.635 | 3.455 | 5.348 | 7.841 | 12.59 | 16.81 |
| ν = 7 | 1.239 | 2.167 | 4.255 | 6.346 | 9.037 | 14.07 | 18.48 |
| ν = 8 | 1.646 | 2.733 | 5.071 | 7.344 | 10.22 | 15.51 | 20.09 |
| ν = 9 | 2.088 | 3.325 | 5.899 | 8.343 | 11.39 | 16.92 | 21.67 |
| ν = 10 | 2.558 | 3.940 | 6.737 | 9.342 | 12.55 | 18.31 | 23.21 |
| ν = 11 | 3.053 | 4.575 | 7.584 | 10.34 | 13.70 | 19.68 | 24.72 |
| ν = 12 | 3.571 | 5.226 | 8.438 | 11.34 | 14.85 | 21.03 | 26.22 |
| ν = 15 | 5.229 | 7.261 | 11.04 | 14.34 | 18.25 | 25.00 | 30.58 |
| ν = 20 | 8.260 | 10.85 | 15.45 | 19.34 | 23.83 | 31.41 | 37.57 |
| ν = 30 | 14.95 | 18.49 | 24.48 | 29.34 | 34.80 | 43.77 | 50.89 |
| ν = 50 | 29.71 | 34.76 | 42.94 | 49.33 | 56.33 | 67.50 | 76.15 |
| ν > 30 | ν + sqrt(2 ν ) · ایکس پ+ 2/3 ایکس 2 پ– 2/3 + O(1/sqrt( ν )) | ||||||
| ایکس پ = | -2.33 | -1.64 | -0.674 | 0.00 | 0.674 | 1.64 | 2.33 |
قابل قبول در نظر بگیرید پ از 10% تا 90%.
اگر χ 2 گسترش یابد. بسیار بیشتر از نظریه χ 2. (به این معنا که پبزرگ است)، سپس ژنراتور راضی نمی کندنیاز به توزیع یکنواخت، از مقادیر مشاهده شده n مناز نظر تئوری خیلی دور شوید پ من · ن و نمی توان آن را تصادفی در نظر گرفت. به عبارت دیگر، چنین فاصله اطمینان زیادی ایجاد می شود که محدودیت های اعداد بسیار شل می شود، الزامات اعداد ضعیف هستند. در این صورت یک خطای مطلق بسیار بزرگ مشاهده خواهد شد.
حتی D. Knuth در کتاب خود "هنر برنامه نویسی" اشاره کرد که داشتن χ 2 exp. کوچک نیز به طور کلی خوب نیست، اگرچه در نگاه اول از نقطه نظر یکنواختی قابل توجه به نظر می رسد. در واقع، یک سری از اعداد 0.1، 0.2، 0.3، 0.4، 0.5، 0.6، 0.7، 0.8، 0.9، 0.1، 0.2، 0.3، 0.4، 0.5، 0.6، ... را در نظر بگیرید - آنها از نظر ایده آل هستند. یکنواختی، و χ 2 exp. عملاً صفر خواهد بود، اما بعید است که آنها را تصادفی تشخیص دهید.
اگر χ 2 گسترش یابد. بسیار کمتر از نظریه χ 2. (به این معنا که پ- کمی)، سپس ژنراتور راضی نمی کندنیاز به توزیع یکنواخت تصادفی، از مقادیر مشاهده شده n منخیلی نزدیک به نظری پ من · ن و نمی توان آن را تصادفی در نظر گرفت.
اما اگر χ 2 exp. در محدوده معینی بین دو مقدار تئوری χ 2 قرار دارد. ، که برای مثال مطابقت دارند پ= 25٪ و پ= 50٪، پس می توانیم فرض کنیم که مقادیر اعداد تصادفی تولید شده توسط سنسور کاملا تصادفی هستند.
علاوه بر این، باید در نظر داشت که همه ارزش ها پ من · ن باید به اندازه کافی بزرگ باشد، برای مثال، بیشتر از 5 (به طور تجربی یافت می شود). تنها در این صورت (با یک نمونه آماری به اندازه کافی بزرگ) می توان شرایط تجربی را رضایت بخش در نظر گرفت.
بنابراین، روش تایید به شرح زیر است.
آزمون های استقلال آماری
1) بررسی فراوانی وقوع یک رقم در یک دنباله
یک مثال را در نظر بگیرید. عدد تصادفی 0.2463389991 از ارقام 2463389991 و عدد 0.5467766618 از ارقام 5467766618 تشکیل شده است.
واضح است که احتمال نظری پ منسقوط منرقم ام (از 0 تا 9) 0.1 است.
2) بررسی ظاهر سری اعداد یکسان
با نشان دادن n Lتعداد سری از ارقام متوالی یکسان طول L. همه چیز باید بررسی شود Lاز 1 تا متر، جایی که متریک عدد مشخص شده توسط کاربر است: حداکثر تعداد ارقام یکسان در یک سری.
در مثال "24633899915467766618"، 2 سری به طول 2 (33 و 77) یافت شد، یعنی n 2 = 2 و 2 سری از طول 3 (999 و 666)، یعنی. n 3 = 2 .
احتمال یک سری با طول Lبرابر است با: پ L= 9 10 - L (نظری). یعنی احتمال وقوع یک سریال با طول یک کاراکتر برابر است با: پ 1 = 0.9 (تئوری). احتمال نمایش یک سریال دو شخصیتی به صورت زیر است: پ 2 = 0.09 (نظری). احتمال نمایش یک سریال سه شخصیتی این است: پ 3 = 0.009 (تئوری).
به عنوان مثال، احتمال وقوع یک سریال با طول یک کاراکتر برابر است با پ L= 0.9، زیرا از 10 کاراکتر فقط یک کاراکتر می تواند وجود داشته باشد و فقط 9 کاراکتر (صفر شمارش نمی شود). و احتمال اینکه دو کاراکتر یکسان "XX" در یک ردیف به هم برسند 0.1 0.1 9 است، یعنی احتمال 0.1 که شخصیت "X" در موقعیت اول ظاهر شود در احتمال 0.1 ضرب می شود که همان کاراکتر در موقعیت دوم "X" ظاهر می شود و در تعداد این ترکیبات 9 ضرب می شود.
فراوانی وقوع سری ها با توجه به فرمول "خی دو" که قبلاً با استفاده از مقادیر مورد تجزیه و تحلیل قرار داده ایم محاسبه می شود. پ L .
توجه: ژنراتور را می توان چندین بار بررسی کرد، اما بررسی ها کامل نیستند و تضمین نمی کنند که ژنراتور اعداد تصادفی تولید می کند. به عنوان مثال، ژنراتوری که دنباله 12345678912345 را تولید می کند، در طول بررسی ها ایده آل در نظر گرفته می شود، که بدیهی است که کاملاً درست نیست.
در خاتمه متذکر می شویم که فصل سوم کتاب «هنر برنامه نویسی» نوشته دونالد ای. کنوت (جلد 2) کاملاً به مطالعه اعداد تصادفی اختصاص دارد. این روشهای مختلف برای تولید اعداد تصادفی، معیارهای آماری برای تصادفی بودن، و تبدیل اعداد تصادفی به طور یکنواخت به انواع دیگر متغیرهای تصادفی را بررسی میکند. بیش از دویست صفحه به ارائه این مطالب اختصاص یافته است.
دریافت و تبدیل اعداد تصادفی
دو راه اصلی برای بدست آوردن اعداد تصادفی وجود دارد:
1) اعداد تصادفی توسط یک پیوست الکترونیکی ویژه (حسگر اعداد تصادفی) نصب شده بر روی رایانه تولید می شوند. اجرای این روش تقریباً به هیچ عملیات اضافی نیاز ندارد، به جز دسترسی به مولد اعداد تصادفی.
2) روش الگوریتمی - بر اساس تشکیل اعداد تصادفی در خود ماشین از طریق یک برنامه خاص. نقطه ضعف این روش مصرف اضافی زمان رایانه است، زیرا در این حالت دستگاه عملیات ستاپ باکس الکترونیکی را خود انجام می دهد.
برنامه تولید اعداد تصادفی توسط قانون توزیع معین می تواند دست و پا گیر باشد. بنابراین، اعداد تصادفی با قانون توزیع معین معمولاً نه به طور مستقیم، بلکه با تبدیل اعداد تصادفی که دارای مقداری توزیع استاندارد هستند، به دست می آیند. اغلب چنین توزیع استانداردی توزیع یکنواخت است (به راحتی به دست می آید و به راحتی به قوانین دیگر تبدیل می شود).
به دست آوردن اعداد تصادفی با یک قانون یکنواخت برای به دست آوردن با کمک یک جعبه تنظیم الکترونیکی بسیار سودمند است، که رایانه را از هزینه های اضافی زمان رایانه آزاد می کند. دستیابی به توزیع کاملاً یکنواخت در رایانه به دلیل شبکه بیت محدود غیرممکن است. بنابراین، به جای مجموعه ای پیوسته از اعداد در بازه (0، 1)، یک مجموعه گسسته از 2nاعداد، کجا n- عمق بیت کلمه ماشین.
قانون توزیع چنین جمعیتی نامیده می شود شبه یکنواخت . در n³20، تفاوت بین قوانین یکنواخت و شبه یکنواخت ناچیز می شود.
برای بدست آوردن اعداد تصادفی شبه یکنواخت از 2 روش استفاده می شود:
1) تولید اعداد تصادفی با استفاده از جعبه تنظیم الکترونیکی با شبیه سازی برخی از فرآیندهای تصادفی.
2) بدست آوردن اعداد شبه تصادفی با استفاده از الگوریتم های خاص.
برای گرفتن nاعداد تصادفی باینری با ارزش طبق روش اول، دنباله ای از متغیرهای تصادفی مستقل مدل شده است. z iدنباله حاصل از 0 و 1، اگر به عنوان یک عدد کسری در نظر گرفته شود، یک مقدار تصادفی از توزیع شبه یکنواخت در بازه (0، 1) است. روش های سخت افزاری برای به دست آوردن این اعداد تنها در نحوه پیاده سازی متفاوت است. z i.
یکی از روش ها بر اساس شمارش تعداد ذرات رادیواکتیو در یک دوره زمانی معین است. Dt، اگر تعداد ذرات برای Dtحتی پس از آن z i=1 ، و اگر فرد باشد، پس z i=0 .
روش دیگر از اثر نویز یک لوله خلاء استفاده می کند. تثبیت مقدار ولتاژ نویز در نقاط خاصی از زمان تی من، مقادیر متغیرهای تصادفی مستقل را بدست می آوریم U(t i)، یعنی ولتاژ (Volt).
مقدار z iتعیین شده توسط قانون:
جایی که آمقداری از ولتاژ آستانه است.
مقدار آمعمولاً از شرایط انتخاب می شود:
نقطه ضعف روش سخت افزاری این است که اجازه نمی دهد از روش دوبار اجرا برای کنترل عملکرد الگوریتم برای حل هر مشکلی استفاده شود، زیرا نمی توان همان اعداد تصادفی را در طول اجرای دوم به دست آورد.
شبه تصادفیشماره تماس های تولید شده بر روی رایانه با کمک برنامه های خاص به صورت تکراری: هر شماره تصادفی با استفاده از تبدیل های خاص از شماره قبلی به دست می آید.
ساده ترین این تبدیل ها به شرح زیر است. بگذار تعدادی وجود داشته باشد n- عدد باینری بیت از بازه nн (0، 1).ما آن را مربع، و ما در حال حاضر 2nعدد بیت میانگین را انتخاب کنید nترشحات از این طریق به دست می آید n– عدد بیت و مقدار جدید عدد تصادفی خواهد بود. دوباره آن را مربع می کنیم و غیره. چنین دنباله ای شبه تصادفی است، زیرا از نقطه نظر نظری، تصادفی نیست.
عیب الگوریتمهای تکراری این است که دنبالههایی از اعداد تصادفی میتوانند منحط شوند (به عنوان مثال، ما فقط یک دنباله صفر یا یک دنباله از یکها را دریافت میکنیم، یا ممکن است تناوب ظاهر شود).
 ژیمناستیک تنفسی در کلاس های موسیقی در یک توسعه روش شناختی داو با موضوع فناوری های صرفه جویی در سلامت در یک داو در کلاس های موسیقی
ژیمناستیک تنفسی در کلاس های موسیقی در یک توسعه روش شناختی داو با موضوع فناوری های صرفه جویی در سلامت در یک داو در کلاس های موسیقی VKontakte: تاریخ، موفقیت، حقایق شناخته شده و کمتر شناخته شده حقایق غیر معمول vk
VKontakte: تاریخ، موفقیت، حقایق شناخته شده و کمتر شناخته شده حقایق غیر معمول vk کلاس کارشناسی ارشد "کاربرد اشکال غیر سنتی فناوری های صرفه جویی در سلامت در فعالیت های موسیقی داو، در چارچوب موسسه آموزشی ایالتی فدرال"
کلاس کارشناسی ارشد "کاربرد اشکال غیر سنتی فناوری های صرفه جویی در سلامت در فعالیت های موسیقی داو، در چارچوب موسسه آموزشی ایالتی فدرال"